I blog about anything I find interesting, and since I have a lot of varied interests, my blog entries are kind of all over the place. You can browse my tags to sort them by topic and see which ones I frequently write about, or the archive has a complete history of my posts, dating back to 2008!
Besides my blog, I have pages for my creative projects, which are linked to on the navigation bar.
I write a lot about Linux and Android, Minecraft, and I like to rant about stuff. Generally anything that makes me curious. Also check out my Bookmarks for all sorts of cool websites about various topics I'm interested in.
For the geeks: this website respects your privacy and doesn't run any third party ads or analytics. This site speaks HTTP and doesn't require any JavaScript to work.
Webcam Streaming in Perl/Tk (Linux)Late last week I started thinking about how to access a webcam device from within Perl. I have no direct need of such capability at the time being but I wanted to know how to do it in case I wanted to do something in the future involving webcams.
A few years ago when I used mostly Windows I found EZTwain, a DLL library for accessing a webcam in Windows using the TWAIN protocol (which as I understand is obsolete by now). The DLL was a pain in the butt to use and I couldn't get it to work how I wanted it to (it insisted on displaying its own GUI windows instead of allowing my Perl script to directly pull a frame from it without a GUI).
Besides that there's pretty much no libraries Perl has been built to use yet that can access a webcam. So, I started looking into using third-party programs such as ffmpeg and mplayer/mencoder to provide the hardware layer for me so that Perl can get just the jpeg images out and do with them what it needs.
Of these programs I wanted to use ffmpeg the most, because I know for sure there's an ffmpeg.exe for Windows, which might mean that whatever code I come up with might be reasonably portable to Windows as well.
After some searching I found some command-line sorcery for using ffmpeg over SSH to activate the camera on a remote computer and stream the video from it over SSH to the local system, and display it in mplayer:
ssh user@remoteip ffmpeg -b 100K -an -f video4linux2 -s 320x240 -r 10 -i /dev/video0 -b 100K -f ogg - | mplayer - -idle -demuxer ogg
Using the basic ffmpeg command in there, along with some hours of research and poking around, I eventually came up with a command that would activate the webcam and output a ton of jpeg images with consecutive file names, of each frame of video that the camera recorded:
ffmpeg -b 100K -an -f video4linux2 -s 640x480 -r 10 -i /dev/video0 -b 100K -f image2 -vcodec mjpeg test%d.jpg
The mjpeg codec (or "motion jpeg"), in ffmpeg, really means it's a bunch of jpeg images all combined together one after the other (the start of each jpeg image can be seen in hex by looking for the magic number, 0xFFD8). The "image2" format here means that each frame from the mjpeg stream gets written to an individual image file, in the format test%d.jpg where %d is a number that goes up for each image written.
By changing the image2 to image2pipe instead, the output (all the jpeg images in the mjpeg stream) is sent through the program's standard output, so it can be piped into another program, or read from in Perl.
So in Perl I opened a pipe that executes this command and have the script read from it, reading all the jpeg images and then displaying them in a Perl/Tk window as they come in. In effect: a live webcam stream, where Perl is entirely in control of the jpegs as they come in from ffmpeg and can do with them whatever it wants!
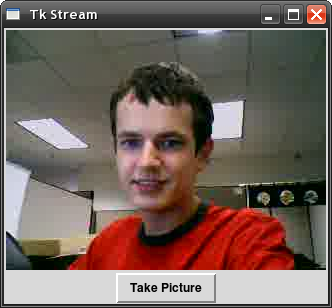
I added a button to my GUI for taking a snapshot and saving it to disk (in actuality, as each complete image is read and displayed, it's kept around in memory until the next image is read and displayed... so this button just saves the last full image to disk).
Here's my proof of concept Perl code:
#!/usr/bin/perl -w
# Perl/Tk Webcam Streamer and Snapshot Taker
# Proof of Concept
# Author: Casey Kirsle, http://www.cuvou.com/
use Tk;
use Tk::JPEG;
use MIME::Base64 "encode_base64";
# Some things that might need to be configured.
my $device = shift(@ARGV) || "/dev/video0";
if ($device =~ /^\// && !-e $device) {
die "Can't see video device: $device";
}
# Tk MainWindow
my $mw = MainWindow->new (
-title => 'Tk Stream',
);
$mw->protocol (WM_DELETE_WINDOW => \&onExit);
# A label to display the photos.
my $photo = $mw->Label ()->pack();
# A button to capture a photo
my $capture = $mw->Button (
-text => "Take Picture",
-command => \&snapshot,
)->pack();
$mw->update();
You can download it here. It should run on any Linux distribution and it depends on having Perl/Tk and ffmpeg installed, and the video4linux2 system (any modern distro will have that).
In the ffmpeg command here you'll see I also piped the output into a quick Perl script that substitutes all the jpeg headers so that they begin with "KIRSLESEP" -- this was to make it easier to split the jpegs up while reading from the stream.
Since this uses ffmpeg and there's an ffmpeg.exe for Windows, this might work on Windows (you'll definitely need to modify the arguments sent to the ffmpeg command, though). I don't currently have access to a Windows machine with a webcam, though, so I can't work on that just yet.
Anyway, here it is: webcam access in Perl!
I, along with pretty much every other savvy computer user, never do the "Recommended" installation of software and always go with the "Custom Installation" route, so that I can opt out of installing unnecessary toolbars and other spyware/adware that comes with free Windows software. But does the Average Joe Windows user know that? Definitely not; the Average Joe just clicks through the install dialogs until the program he wants is installed, not knowing that he also just sold his soul to the devil by installing all manner of malicious spyware on his system.
So, I conducted an experiment.
I installed Windows XP on a virtual machine, and installed only a small selection of software that the average user would likely use, and went with all the "Recommended" installation options for every program installed. Altogether, I only installed 9 programs, and most of those were something everybody can say they've installed: instant messengers.
Memory: 256 MB
HDD Space: 10 GB
I installed a fresh copy of Windows XP, installed the VirtualBox guest additions, and used this as the baseline for a "vanilla" Windows XP installation -- a fresh, clean, pure instance of Windows with nothing really installed on it.
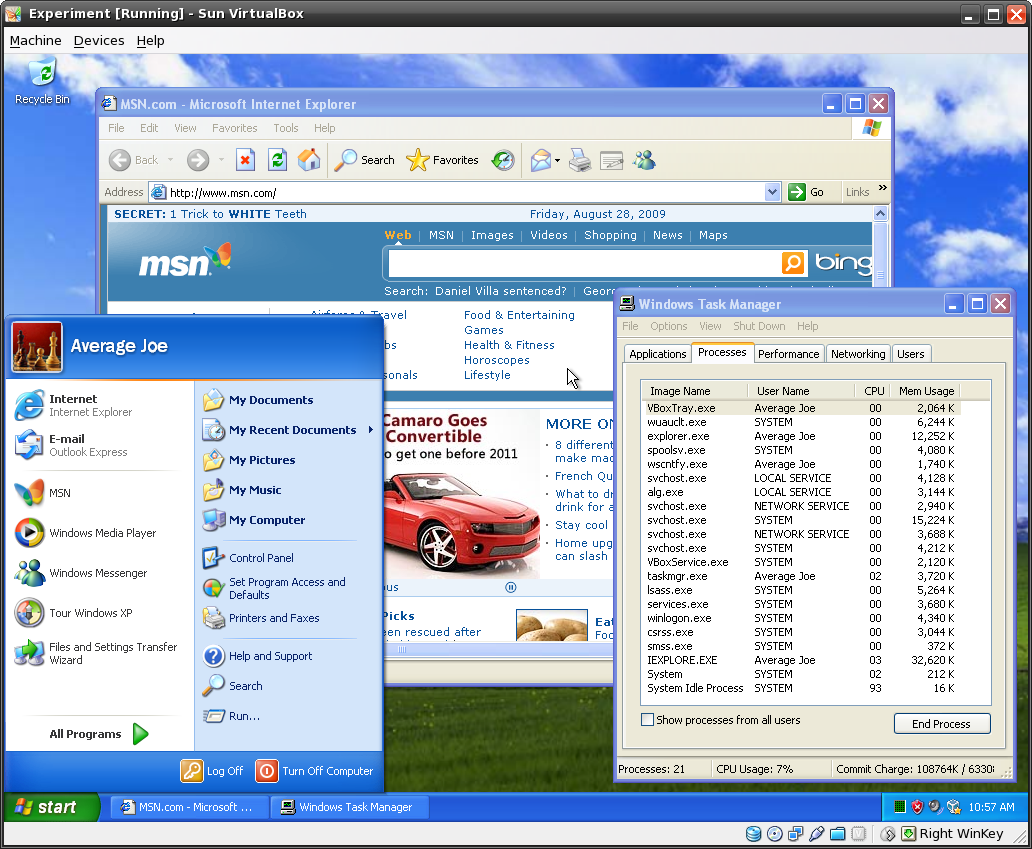
[click for larger screenshot]
In our fresh vanilla Windows XP install, we see the default desktop, the start menu, the Task Manager with few enough tasks in it that we don't even need a scrollbar, and a default Internet Explorer 6 window with MSN as its homepage.
Then, I started installing some software.
Then I installed Yahoo! Messenger 9.0.0.2162 - this installed Yahoo Messenger, put an icon on my desktop, installed the Yahoo! Toolbar, and set my homepage and search engine to Yahoo.
Then, Windows Live Messenger 2009 (Build 14.0.8089.726) - this one didn't install a desktop icon, but it set my homepage in IE back to MSN.com and changed my search engine back to Bing.
These are the three most common instant messengers that most people use. So, I went and installed other essential software:
Sun Java Runtime Environment, JRE 6 version 15. Java also took the liberty of installing the Bing Toolbar in my Internet Explorer.
Then I downloaded WinZip 12.1 Free Edition. Windows XP comes with built-in support for zip files, but Average Joe is bound to come across archives of other types and will be told to get WinZip. WinZip installed for me the Google Toolbar in Internet Explorer.
Then, the Adobe Flash Player 10.0.32.18 - this is, so far, the only piece of software that installs what it says and nothing more. It's also the only thing I've installed in my experiment that installed only what I wanted it to.
Finally, I got a couple extra instant messengers installed: Skype 4.1 and ICQ 6.5 - Skype installed the Google Chrome web browser and ICQ installed the ICQ Toolbar and set my homepage and search engine to ICQ.
At this point, I have only installed 8 programs; 8 programs that Average Joe End User is likely to install. Using the default options on all the installers, my system is now fscked up already. But why stop there? Average Joe also needs an antivirus suite, with all this scare going around about viruses.
So, Average Joe installs AVG Free because Average Joe is a cheapass who can't afford Norton or McAfee. AVG may be well-intentioned, but that didn't stop it from installing the AVG Toolbar "Powered by Yahoo!" into my Internet Explorer as well as changing my search engine to AVG Search.
So, what's the damage? 9 programs, and this is what my system looks like:
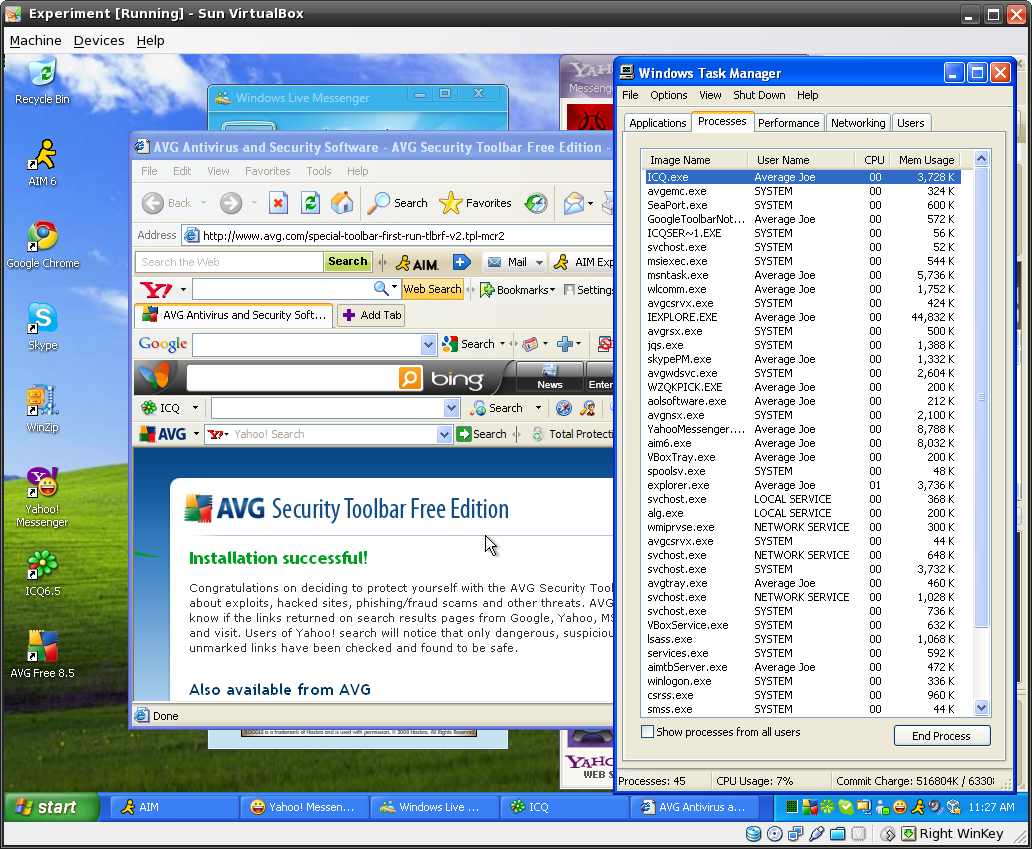
[click for larger screenshot]
My Task Manager list has grown exponentially; I have to resize it vertically as tall as it will go, and even then there's still a scrollbar. And do you see the IE window in all that mess? It's completely being murdered under the weight of the 7 different toolbars taking up HALF of the vertical screen real estate.
This is only 9 programs being installed. For a quick list, here they are again:
[click for larger screenshot]
This, THIS is why Windows sucks. All Windows software installs all this crapware along with it, and all this crapware competes with each other (just look how many times my search engine had been changed).
This is the list of toolbars in IE, from top to bottom, which take up 50% of my 1024x768 vertical resolution:
19 cookies in Internet Explorer. Cookies!!!
The only thing AdAware found were cookies left by ad banners. No adware? No spyware? Are you kidding me!?
So, how do the startup programs look? Well, I'll tell you that rebooting this virtual machine is miserable. With all these programs starting up when the desktop loads, nothing productive can be done for a full 10 minutes. Here's the breakdown:
After this, the startup items were:
It should be noted here that free, open source software, almost never comes with crap like this. If you stick to fine programs like Firefox and Pidgin you can install them without worrying about what other crap they'll bring along with them.
I hate Windows.
I got to the office and checked my e-mail and saw that TekTonic (my web hosting company) forwarded an e-mail to me that was sent to their abuse department from another sysadmin, saying that my server's IP has been caught brute-forcing SSH passwords on their server.
So I logged into my server to check things out. My guesses at this point were either: somebody on my server has a weak SSH password, and one of those automated password-guessing bots has cracked it and their account got pwned; or else somebody on my server had something insecure on their site, such as a PHP app or some SSI code, that got compromised and used to attack my server.
After pruning the SSH logs and seeing nothing suspicious, I noticed that the Apache web service was down (so all sites on the server were offline). Apache's been doing this at random intervals so I didn't think much of it just yet and started Apache back up, and then thought to check its global error log file.
Apart from the usual errors that Apache logs here (404 Not Found, etc.) there was other text in the log file that was the output of some commands that would be run at a terminal. Commands like wget (to download files off the Internet), chmod (there were some errors like "chmod: invalid mode 'x'" indicating a badly entered chmod command), and perl (attempting to execute a Perl script).
From reading this in the error log it became apparent that somebody was causing Apache (or at least the user that Apache runs as) to execute system commands. With that, they downloaded a tarball containing exploits from a Geocities site, a tarball containing a backdoor/trojan, and a tarball containing something that they used to "phone home" - probably to make the process of entering commands on my server easier.
In Apache's access log file I was able to see how they were doing this; they were abusing a flaw in phpMyAdmin that allowed them to execute these commands. So, I was right: somebody had a PHP application on their site and this app was used to break into the server. But that somebody was me. :(
So, I was able to see what HTTP requests they were making that was causing phpMyAdmin to execute their commands, and therefore I was able to see all the commands they entered -- or rather, the ones they entered by abusing phpMyAdmin. If the phone home script was indeed used to execute additional commands, they could've run even more after that point (I'm assuming they did, because the initial e-mail I got was about my server guessing SSH passwords on another, and nothing that happened through phpMyAdmin was responsible for that).
I later found out from TekTonic that when they first got the complaint they logged in and killed the Apache-owned process that was brute forcing the SSH passwords. This would explain why Apache was down when I logged in. But the fact that this hacker was running additional commands through the backdoor script that I have no logs of made me decide that reimaging the server would be the best solution. I used to work at a web hosting company and when a customer server got pwned, reinstalling the operating system was the only way to be sure no rootkits were left behind -- especially considering that rootkits these days are pretty crafty and can hide from being listed in the running processes.
I e-mailed the abuse departments at Geocities telling them that one of their users is hosting backdoors and the abuse department of the ISP that controls the IP address of the hacker who broke into my server. Hopefully further action will be done on their parts. The hacker probably won't be found (hackers tend to go through proxy servers like there's no tomorrow), but hopefully whatever server that IP address belongs to can be fixed to prevent further use by the hacker to attack other servers.
Anyway,
This is why I don't like PHP. The exploit in phpMyAdmin was because phpMyAdmin has a PHP file that directly runs system commands based on a query string parameter. This file isn't meant to be executed directly (it's named with a ".inc.php" extension, indicating it was intended to be included by another PHP script and not run directly over the web). But this file was available directly over the web, AND it accepted query string parameters, AND executed those on the system. Terrible! In Perl this kind of thing would never fly. If you did request a Perl included file directly, it wouldn't read your query string parameters, because normally the Perl script that includes it would've done that already.
PHP has too many newbies, and newbies write terrible code. phpMyAdmin could've been smarter than this, but the fact that this happens shows that phpMyAdmin wasn't coded very well at all, probably because its coders are incompetent PHP kiddies.
Anyway, this time around, PHP is NOT installed on my server AT ALL. And if anybody on my server asks for it, to get something like WordPress installed for instance, I'll just kindly point them to MovableType as a Perl alternative to WordPress. WordPress might be a decent PHP application, but it's still a PHP application and I officially will not trust any PHP app written by anyone other than real programmers to be installed on this server again.
PHP programmers who only program PHP basically can be assumed to be completely incompetent and to build in gaping, shameless security holes like what phpMyAdmin had: a script that directly sends query string parameters into a system command unfiltered. PHP programmers who know other programming languages that aren't as newbish as PHP (Perl, for instance) are probably better at coding secure PHP, but besides that I am officially boycotting PHP coders and their applications.
From my time spent working at a web hosting company, I know that the best way to be sure yer server isn't infected with a rootkit is to reinstall the operating system completely. So, that's what happened, and all in all it meant a few hours of downtime. I'm currently restoring all the sites on the server. Cuvou.com is mainly fully restored now, except the traffic monitoring code isn't put back in place yet so ya won't be able to see how many hits the site's getting just yet.
Update #2 (12/02/2014): I've updated ProgramV 0.08 and released a new version, 0.09, which should work out-of-the-box on modern Perl. If you're interested in ProgramV, check it out on GitHub or read my blog post about the update.
The original blog post follows.
Numerous years ago (2002 or 03) while I was a newb at programming my own chatterbots in Perl (and a newb at Perl in general), there was this program called Alicebot Program V - an implementation of an Alice AIML chatbot programmed in Perl.
When I moved from RunABot (hosted AIML bots) and Alicebot Program D (a Java AIML bot) to Perl, I had to give up using AIML for my bots' response engines because there weren't any simple Perl solutions for parsing AIML code. There was only Program V, and Program V is a monster! I could never figure out how to get it to actually run, and, while it had a dozen Perl modules with it that deal with the AIML files, these modules are too integrated together to separate and use in another program.
And then Program V's site went down and for several years I couldn't find a copy of Program V anymore to give it another shot.
Since I effectively could not use AIML for my Perl bots, I eventually developed an alternative bot response language called RiveScript, and it's text-based instead of XML-based, so it's super easy to deal with. At this point I don't care much for AIML any more, because my RiveScript is more powerful than it anyway.
The only thing RiveScript is missing though is Alice - the flagship bot personality of AIML. Alice has about 40,000 patterns that it can respond to. Users chatting with Alice won't get bored with the conversation for a long, long time. Alice has a large enough reply set that you'll have to chat with it a lot before you can start predicting how she might reply to your next message.
RiveScript, being (relatively) new (and not yet as popular as AIML), hasn't seen any large projects like Alice. Alice was written by Dr. Wallace, who created AIML; should I, as the creator of RiveScript, create an Alice-sized reply base myself? Ha. I wish I had that kind of free time on my hands.
So for a really long period of time I was trying to create an AIML-to-RiveScript translator, so that Alice's 40,000 responses of AIML code could become 40,000 responses of RiveScript code. I've finally accomplished this with a really good degree of success recently. So mission accomplished.
Now, while searching for something unrelated, I managed to come across a site that hosted a copy of the Program V code. Now that I'm much more awesome at Perl than I was back then, I downloaded it and tried getting it set up. It took a bit of tinkering (it was programmed on Perl 5.6 and some things have changed between then and 5.10) but I got it up and running.
Program V works in two parts: first you run a "build script," which reads and processes the AIML code and builds a kind of database file (really it's just the result of Data::Dumper, dumping out a large Perl data structure). And then you run the actual bot script, which just loads this data structure from disk. This is because the Alice AIML set (40K replies) takes about 3 to 4 minutes to load, but the Perl data structure takes milliseconds to load. So you build it first to save lots of time when actually running it.
I was impressed at how fast the bot could reply, too. Most of its replies were coming back in 8 milliseconds or less. In contrast, when I load Alice's brain in RiveScript... it takes 5 seconds to load all the RiveScript code from disk (much faster than Program V's loading of AIML), and then Alice will usually reply in less than 1 second, but longer than 8 milliseconds. So, I had a look at this data structure that Program V creates.
In the data structure, all the patterns in AIML are put into a hash, and categorized by the first word in the pattern. Here's just a snippit:
The following patterns are represented here:
ITS *
ITS BORING
ITS FUN
ITS GOOD *
$data = {
aiml => {
matches => {
'ITS' => [
'* <that> * <topic> * <pos> 17818',
'BORING <that> * <topic> * <pos> 17819',
'FUN <that> * <topic> * <pos> 17820',
'GOOD * <that> * <topic> * <pos> 17821',
],
},
},
};
So, since all these patterns began with the word "ITS", they're all categorized under the "ITS"... each item in the array begins with the rest of the pattern (after the word ITS), and then there's separators for the "that", "topic", and "pos" (position). In all the examples here, these patterns had no 'that' or 'topic' tags associated with them, so there's only *'s here. The position is an array index.The templates (responses to these patterns) are all thrown together into a single large array. All those positions listed in the "matches" structure? Those are array indices.
You might need to know a little Perl to see the performance boost here. A good number of patterns in Alice's brain begin with the same word. So when it's time to match a reply from the human, the program can use the first word in your message as a hash key (say you said "It's good to be the king", it would look up the array above based on the word "ITS"). With Alice's brain, there'd be only a few hundred unique first words to patterns. So this is a relatively small hash, and looking up one of these keys such as "ITS" is really fast. Then, each of the arrays here are relatively small, and the program just loops through them to find out if any of them match your message (taking into account the `that`'s and `topic`s too).
When it finds a match, it has an array index of the template for that match. Pulling an array item by index in Perl is even more wicked fast than a hash. So almost instantaneously you can get a response back.
Compared to the Perl module, RiveScript.pm's, data structure, the one used by Program V is much more efficient. In RiveScript.pm everything is arranged in a hierarchy, sorted by: topic, pattern, reply. RiveScript uses arrays in the end to organize the patterns in the most efficient way possible, but when it comes to actually digging out data from this giant hashref structure, it's a little slower than just using an array like Program V.
Still, though, 1 second response times for a brain that contains 40,000 patterns isn't bad. But I might need to think about recoding RiveScript.pm to use more efficient data structures like Program V.
I have a copy of Program V hosted on RiveScript.com here: programv-0.08.tar.
For those that don't know, Perl 6 is the new version of Perl and is still under rapid development (and has been for several years). However, it's come a long way already. In Spring of 2010 there will be a "useful and usable" release of Perl 6. But for now you can still build it and play around.
Note that there are some dependencies required to build some of these things. Read the "README" files that ship with Parrot and Rakudo for details. On Fedora I needed gcc, make, libicu-devel, and subversion to build everything. Check out Parrot, the virtual machine that Rakudo targets
The Parrot Virtual Machine is a pretty weird program that's supposed to be able to run various different kinds of dynamic languages, including Perl 6. Rakudo Perl 6 uses Parrot, so we need Parrot.
Fedora provides packages for Parrot via the yum database, but I didn't use them; firstly I wanted the latest version and secondly I needed the source code anyway to build Perl 6.
Check out Parrot using svn. Something like this (as root or a user that is able to modify files in /usr/src/svn)...
# mkdir -p /usr/src/svn # cd /usr/src/svn # svn co https://svn.parrot.org/parrot/trunk parrot # cd parrot # perl Configure.pl # make # make test # make installThis installs it to /usr/local/. The next place we want to go is /usr/local/lib/parrot/1.4.0-devel/languages (note the "1.4.0-devel" might be some different version number).
Get Rakudo Perl
# cd /usr/local/lib/parrot/1.4.0-devel/languages # git clone git://github.com/rakudo/rakudo.git # cd rakudo/The Configure.pl script to build Perl 6 requires the "parrot_config" file that came with the source code of Parrot, in the svn repository. So I just made a symbolic link to my svn folder here.
(current dir: /usr/local/lib/parrot/1.4.0-devel/languages/rakudo) # ln -s /usr/src/svn/parrotThen build Perl 6.
(current dir: /usr/local/lib/parrot/1.4.0-devel/languages/rakudo) # perl Configure.pl # makeIf all went well there will be a "perl6" binary in the current directory. I then just made a symlink to it in /usr/bin:
# cd /usr/bin # ln -s /usr/local/lib/parrot/1.4.0-devel/languages/rakudo/perl6Now you can make a test Perl 6 script:
$ cat <<'EOF' > test.pl > #!/usr/bin/perl6 > print "Hello world!\n"; > EOF $ chmod 0755 test.pl $ ./test.plPerl 6 CGI scripts run just fine in the Apache web server too.
I imagine that by Spring 2010 Perl 6 will ship with a "make install" script, possibly some RPMs, and generally be easier to install.
So I've created a web-based converter tool to turn TrueType TTF fonts into OpenType EOT fonts, to go along with my other tools that turn images into favicons and turn images into XBM masks.
You can use the new tool here. As with all the other tools, your converted files are cleared off the server after 24 hours, so don't think about hotlinking your embeddable fonts!
The idea was that there could be a common archive file format (Tyd) that could be used by multiple applications or games, and each application would have its own password for its Tyd archive, that only the application and the developer knows. This would make it at least a little bit difficult for the app's end users to open up the archive and poke around at its contents. Compare this to Blizzard's MPQ archive format used by all their games, where users can easily open them up and get at their contents. With Tyd, they'd need to reverse engineer each application that uses a Tyd archive to open that app's archives.
You can see Archive::Tyd's CPAN page for more details.
This was limited though because, since the whole entire file was encrypted together, the application would need to load the whole archive into memory to be able to use it. So, while it was fine for small archives containing small files, a larger archive would consume too much memory. So forget about storing a lot of MP3s and MPEGs in a Tyd archive unless you're operating a supercomputer.
Also, there was no way to verify that a password to an archive was entered correctly, short of trying to decode it and see if you only get gibberish out of it.
So I started piecing together ideas for a successor to Tyd, which will still be called Tyd (version 2.0). The basic requirements are:
To facilitate "streaming", when the archive is encrypted or compressed, each file is only affected one block at a time. By default the block size is 512 bytes, so when a file is added to an encrypted archive, 512 bytes are encrypted at a time and separately. When reading the file back from the archive, one block at a time is read, decrypted, and returned to the caller (the block size after encryption is surely greater than 512 bytes; when compressed, less than 512 bytes).
For the actual encryption and compression algorithms I'll be using existing CPAN modules to implement known algorithms.
The new Archive::Tyd algorithm is intended to have basically these features:
This way the application can be built to know the public key so it can read the archive, and any user who reverse engineers the application can only get the public key -- so they can get read-only access to the archive, but have a much harder time modifying it or changing its contents without the secret key. IIRC this would be similar to Blizzard's MPQ, in that the DLL that reads MPQ files for their games doesn't include the functions needed to write/modify MPQ files, giving the end users read-only access to the file's contents.
Anyway, no ETA yet, this is a big project. (Well, not really, the heavy lifting of encryption/compression is done by third party modules, all I need to do is program the wrapper code).
@font-face attribute of CSS 3, which allows you to embed a TrueType Font file on a web page, so that the user will see the font on your page even if they don't have the font installed on their computer.This feature has been possible in Internet Explorer since version 4.0, but IE uses a variant of OpenType Font instead of TrueType. IE was the only browser to support such a thing for a long time, so it never really caught on.
Now that Firefox and other CSS3-supporting browsers are implementing @font-face for TTF, we can combine that feature with IE's support for EOT font files and get embeddable fonts to work on both browsers.
I have a demonstration here: Embedded Font Test. This page embeds my Rive font, which is available (in TTF form) from my Fonts page.
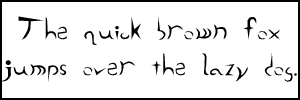
To convert TTF to EOT files, you can use Microsoft's WEFT tool which has been around since the dark ages, but I much prefer ttf2eot, hosted at Google Code. This is a no-nonsense tool that gets straight to the point of converting a font file without the hassle of dialogs that must be clicked through with WEFT. Oh, and there's conveniently a Windows executable already built, just grab it from the Downloads page.
Usage is pretty straightforward:
ttf2eot < Rive.ttf > Rive.eotAnd then embedding the pair of fonts on a page that is compatible with both IE 6 and Firefox 3.5 (and I imagine other CSS3-compliant browsers, though I haven't tested them):
@font-face {
font-family: Rive;
src: url("Rive.eot") /* For IE 6+ */
}
@font-face {
font-family: Rive;
src: url("Rive.ttf") /* For CSS3 browsers inc. Firefox */
}
body {
background-color: #000000;
color: #FF9900;
font-family: Rive;
font-size: 16pt
}
IE 6 knows to ignore the TTF entry, and Firefox knows to ignore the EOT entry, as each browser can't display the opposite type of font.
The cplusplus.com tutorial only covers the syntax of C++, but doesn't go into anything practical, such as working with more than one source file, or how header files work, or how to compile a program that has multiple files. The tutorial at learncpp.com though covers all of these things and then some -- it even explains how C++ programs are organized and a bunch of other helpful techniques that clears up a lot of the fuzziness that other tutorials leave ya with.
So after a week and change, I've gotten about halfway through the tutorials and am attempting to write my own programs from scratch -- actual programs, not tutorial-like things. So, I've decided to start piecing together a CyanChat library. Why CyanChat? Because of its simplicity:
Programming this CyanChat library so far is a bit more tricky than it was in Perl and Java. There is a full C++ CyanChat client available named Magenta, but looking at its source code doesn't help me very much -- this is a Windows application, and the source file that handles the sockets is an override of the Win32 CSocket library, which is Windows-specific. I want to use something cross-platform.
Right now I'm using the rudesocket C++ library, although I may need to ditch it for something different, because its setTimeout() function doesn't seem to work and so reading from the socket hangs until the server sends data. This isn't scalable.
When I get the library completed, I'll try building it on Windows to get that experience (that'll be a blast...), and then I'll attempt to build a dynamic Windows DLL file from it -- and then link that DLL into Perl using Win32::API -- to see that everything is successful.
My eventual goal in C++ programming is to build a RiveScript interpreter library in it, and build it as a dynamic DLL, so that practically every programming language will then be able to link it and use it (or C/C++ programs can statically link it from its source code if they want). I could even create a Perl module named RiveScript::XS, which compiles statically with the C++ RiveScript interpreter, which might give it additional speed over the pure-Perl RiveScript module -- or again, just to see that it all works how I want it to.
0.0020s.
![]()