I decided to take a serious look at the HTML::Defang module. It's supposed to take some arbitrary HTML input and sanitize it, removing anything potentially malicious in the process (attempts to execute JavaScript code, embedding of iframes, applets, etc.)
It does a pretty decent job, but I found one thing it doesn't handle very well by default. In CSS code, it will attempt to comment out an attribute if you attempt to use JavaScript with it. Some example input:
<span style="background-image: url('javascript:alert(1)')">
HTML::Defang will turn that into this:
<span style="/*background-image: url('javascript:alert(1)')*/">
But, if you begin and end your CSS attribute with an end-comment and start-comment instead, HTML::Defang leaves the code looking like this:
<span style="/**/background-image: url('javascript:alert(1)')/**/">
Now, granted, this sort of exploit only really hits Internet Explorer users (at least for older versions of IE), but it is a pretty big issue still. This is basically how Samy pwned MySpace, after all.
Anyway, I've written a test CGI script for HTML::Defang: you can try to break it here. I added a custom CSS handler that will neutralize JavaScript attempts from the CSS code to handle that problem I found in HTML::Defang. You can see the source code by clicking the link at the bottom of that page.
If anybody finds a way to get JavaScript to execute on that page, let me know. :) I've tried all the usual tricks and haven't found a loophole yet.
This is a re-do of my previous blog post about Perl upload progress bars - my previous approach was completely wrong. By the time $q->upload(); is used, the file has already been received and stored in a temporary location, and so the "progress bar" in this case is really just gauging how fast the server can copy the file from one place to another on its hard drive.
So this post is how to really do a real working file uploader progress bar in Perl.
The basic steps required to do this include:
$q->upload(); and everything like before.The source code needed for this is still amazingly short and concise, compared to the source codes you'll get when you download solutions from elsewhere.
Implementing this doesn't require any special Apache handlers or mod_perl or anything fancy like that.
Sources:
upload.html<!DOCTYPE html>
<html>
<head>
<title>Upload Test</title>
<style type="text/css">
body {
background-color: #FFFFFF;
font-family: Verdana,Arial,sans-serif;
font-size: small;
color: #000000
}
#trough {
border: 1px solid #000000;
height: 16px;
display: block;
background-color: #DDDDDD
}
#bar {
background-color: #0000FF;
background-image: url("blue-clearlooks.png");
border-right: 1px solid #000000;
height: 16px
}
</style>
</head>
<body>
<h1>File Upload Test</h1>
<div id="progress-div" style="display: none; width: 400px; margin: auto">
<fieldset>
<legend>Upload Progress</legend>
<div id="trough">
<div id="bar" style="width: 0%"></div>
</div>
Received <span id="received">0</span>/<span id="total">0</span> (<span id="percent">0</span>%)
</fieldset>
</div>
<div id="upload-form" style="display: block; width: 600px; margin: auto">
<fieldset>
<legend>Upload a File</legend>
<form name="upload" method="post" action="upload.cgi" enctype="multipart/form-data" onSubmit="return startUpload()" id="theform">
<input type="hidden" name="do" value="upload">
<table border="0" cellspacing="0" cellpadding="2">
<tr>
<td align="left" valign="middle">
Session ID<span style="color: #FF0000">*</span>:
</td>
<td align="left" valign="middle">
<input type="text" size="40" name="sessid" id="sessid" readonly="readonly">
</td>
</tr>
<tr>
<td align="left" valign="middle">
File:
</td>
<td align="left" valign="middle">
<input type="file" name="incoming" size="40">
</td>
</tr>
</table><p>
<input type="submit" value="Upload It!"><p>
<small>
<span style="color: #FF0000">*</span> Randomly generated by JavaScript. In practice this would be
randomly generated by server-side script and "hard-coded" into the HTML you see on this page.
</small>
</fieldset>
</div>
<div id="debug"></div>
<script type="text/javascript">
// a jquery-like function, a shortcut to document.getElementById
function $(o) {
return document.getElementById(o);
}
// called on page load to make up a session ID (in real life the session ID
// would be made up via server-side script and "hard-coded" in the HTML received
// by the server, thus it wouldn't require javascript at all)
function init() {
// Make up a session ID.
var hex = [ "0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"A", "B", "C", "D", "E", "F" ];
var ses = "";
for (var i = 0; i < 8; i++) {
var rnd = Math.floor(Math.random()*16);
ses += hex[rnd];
}
$("sessid").value = ses;
// we set the form action to send the sessid in the query string, too.
// this way it's available inside the CGI hook function in a very easy
// way. In real life this would probably be done better.
$("theform").action += "?" + ses;
}
window.onload = init;
// This function is called when submitting the form.
function startUpload() {
// Hide the form.
$("upload-form").style.display = "none";
// Show the progress div.
$("progress-div").style.display = "block";
// Begin making ajax requests.
setTimeout("ping()", 1000);
// Allow the form to continue submitting.
return true;
}
// Make an ajax request to check up on the status of the upload
function ping() {
var ajax = new XMLHttpRequest();
ajax.onreadystatechange = function () {
if (ajax.readyState == 4) {
parse(ajax.responseText);
}
};
ajax.open("GET", "upload.cgi?do=ping&sessid=" + $("sessid").value + "&rand=" + Math.floor(Math.random()*99999), true);
ajax.send(null);
}
// React to the returned value of our ping test
function parse(txt) {
$("debug").innerHTML = "received from server: " + txt;
var parts = txt.split(":");
if (parts.length == 3) {
$("received").innerHTML = parts[0];
$("total").innerHTML = parts[1];
$("percent").innerHTML = parts[2];
$("bar").style.width = parts[2] + "%";
}
// Ping again!
setTimeout("ping()", 1000);
}
</script>
</body>
</html>
upload.cgi#!/usr/bin/perl -w
use strict;
use warnings;
use CGI;
use CGI::Carp "fatalsToBrowser";
# Make a file upload hook.
my $q = new CGI (\&hook);
# This is the file upload hook, where we can update our session
# file with the dirty details of how the upload is going.
sub hook {
my ($filename,$buffer,$bytes_read,$file) = @_;
# Get our sessid from the form submission.
my ($sessid) = $ENV{QUERY_STRING};
$sessid =~ s/[^A-F0-9]//g;
# Calculate the (rough estimation) of the file size. This isn't
# accurate because the CONTENT_LENGTH includes not only the file's
# contents, but also the length of all the other form fields as well,
# so it's bound to be at least a few bytes larger than the file size.
# This obviously doesn't work out well if you want progress bars on
# a per-file basis, if uploading many files. This proof-of-concept only
# supports a single file anyway.
my $length = $ENV{'CONTENT_LENGTH'};
my $percent = 0;
if ($length > 0) { # Don't divide by zero.
$percent = sprintf("%.1f",
(( $bytes_read / $length ) * 100)
);
}
# Write this data to the session file.
open (SES, ">$sessid.session");
print SES "$bytes_read:$length:$percent";
close (SES);
}
# Now the meat of the CGI script.
print "Content-Type: text/html\n\n";
my $action = $q->param("do") || "unknown";
if ($action eq "upload") {
# They are first submitting the file. This code doesn't really run much
# until AFTER the file is completely uploaded.
my $filename = $q->param("incoming");
my $handle = $q->upload("incoming");
my $sessid = $q->param("sessid");
$sessid =~ s/[^A-F0-9]//g;
$filename =~ s/(?:\\|\/)([^\\\/]+)$/$1/g;
# Copy the file to its final location.
open (FILE, ">./files/$filename") or die "Can't create file: $!";
my $buffer;
while (read($handle,$buffer,2048)) {
print FILE $buffer;
}
close (FILE);
# Delete the session file.
unlink("./$sessid.session");
# Done.
print "Thank you for your file. <a href=\"files/$filename\">Here it is again.</a>";
}
elsif ($action eq "ping") {
# Checking up on the status of the upload.
my $sessid = $q->param("sessid");
$sessid =~ s/[^A-F0-9]//g;
# Exists?
if (-f "./$sessid.session") {
# Read it.
open (READ, "./$sessid.session");
my $data = <READ>;
close (READ);
print $data;
}
else {
print "0:0:0:error session $sessid doesn't exist";
}
}
else {
print "0:0:0:error invalid action $action";
}
You can download my full proof-of-concept test below:
Notice: this code is called "proof of concept"; it is NOT production-ready code. You should NOT download this if all you want is a complete plug-and-play solution you can quickly upload to your web server to get file uploading to work. I wrote this code only to show how to make a file uploader in the simplest way possible; this is useful for developers who only needed to know how this is done and who will write the code themselves to develop their production-ready file uploader.
If you want to treat this as a plug-and-play solution, I'm not your tech support about it. The code was never meant to be secure or useful to allow the general public to upload files through it. Session IDs are made up client side for example which is a bad idea in real use case scenarios, etc.
Here's a random idea that just popped into my head: to help with the security of CGI scripts, certain HTML elements in the forms can be "tagged" in various ways depending on what their function will be once submitted.
So a textarea for leaving a comment can be tagged with name="ta-comment" (ta means textarea), and an input box meant for entering user names only could be tagged with name="user-login", and an input box meant for entering numeric zip codes can be tagged name="num-zipcode".
Then, the CGI script, when it first begins parsing the query string and form parameters, can automatically apply global filters to the inputs based on their tag. This way, every input that might potentially be used to access the filesystem can be filtered so that it doesn't contain any special characters that could introduce a vulnerability in the script, but fields that are meant to be more verbatim (i.e. comment boxes) can be left largely untouched.
# Create a CGI object
my $q = new CGI();
# This will hold your script's parameters
my $args = {};
# Get all the params.
foreach my $what ($q->param) {
my $is = $q->param($what);
# Filter the value based on the tag.
if ($what =~ /^num\-/) {
# Numbers only!
$is =~ s/[^0-9]//g;
}
elsif ($what =~ /^user\-/) {
# Usernames are numbers and letters only!
$is =~ s/[^A-Za-z0-9]//g;
}
elsif ($what =~ /^ta\-/) {
# Textareas turn their line breaks into <br>
$is =~ s/\n/<br>/g;
$is =~ s/\x0d//g;
}
$args->{$what} = $is;
}
So this way, as you write your front-end HTML code and the back-end Perl, you can tag all the inputs based on how the back-end code will plan on using them once submitted, and the code that collects the parameters when the form is submitted will be sure to format them in a consistent way. So, if your web application consistently doesn't allow quotation marks or HTML code in their text boxes, you can make the CGI automatically remove these things from all your incoming fields, and then just specially tag the ones that you want to be treated differently.
It would protect against accidental oversights by the programmer, and the end user can't do anything about it either. If the text box's name is "num-zipcode", the CGI script will always remove non-numbers when submitted and the user can't do anything about it. If they try to rename it with Firebug to be "text-zipcode" or anything like that, your CGI script won't use their version because it's not named as "num-zipcode."
I think I'll try implementing something like this next time I create a new web application.
@font-face attribute of CSS 3, which allows you to embed a TrueType Font file on a web page, so that the user will see the font on your page even if they don't have the font installed on their computer.This feature has been possible in Internet Explorer since version 4.0, but IE uses a variant of OpenType Font instead of TrueType. IE was the only browser to support such a thing for a long time, so it never really caught on.
Now that Firefox and other CSS3-supporting browsers are implementing @font-face for TTF, we can combine that feature with IE's support for EOT font files and get embeddable fonts to work on both browsers.
I have a demonstration here: Embedded Font Test. This page embeds my Rive font, which is available (in TTF form) from my Fonts page.
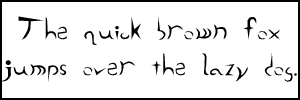
To convert TTF to EOT files, you can use Microsoft's WEFT tool which has been around since the dark ages, but I much prefer ttf2eot, hosted at Google Code. This is a no-nonsense tool that gets straight to the point of converting a font file without the hassle of dialogs that must be clicked through with WEFT. Oh, and there's conveniently a Windows executable already built, just grab it from the Downloads page.
Usage is pretty straightforward:
ttf2eot < Rive.ttf > Rive.eotAnd then embedding the pair of fonts on a page that is compatible with both IE 6 and Firefox 3.5 (and I imagine other CSS3-compliant browsers, though I haven't tested them):
@font-face {
font-family: Rive;
src: url("Rive.eot") /* For IE 6+ */
}
@font-face {
font-family: Rive;
src: url("Rive.ttf") /* For CSS3 browsers inc. Firefox */
}
body {
background-color: #000000;
color: #FF9900;
font-family: Rive;
font-size: 16pt
}
IE 6 knows to ignore the TTF entry, and Firefox knows to ignore the EOT entry, as each browser can't display the opposite type of font.
Update (11/25/09): This method is all wrong. Here is the correct way.
A thread on Tek-Tips came up recently about making a progress bar for a file uploader in Perl.
Investigating the issue more closely, I found a couple of commercial solutions (read: paid for), where even their free edition involves thousands upon thousands of lines of code, spread out across many different files. Nowhere to be found was a simple, straight-to-the-point example of how this could be done.
From poking around at what code I could find, I got the basic gist to it:
It looks like this:
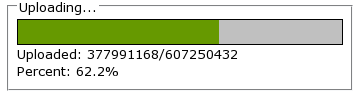
If that sounds complicated, it really isn't. 77 lines for the CGI script, and 126 lines for the HTML page, including the JavaScript (only 60 lines of JavaScript).
The screenshots, code, and download link follow.
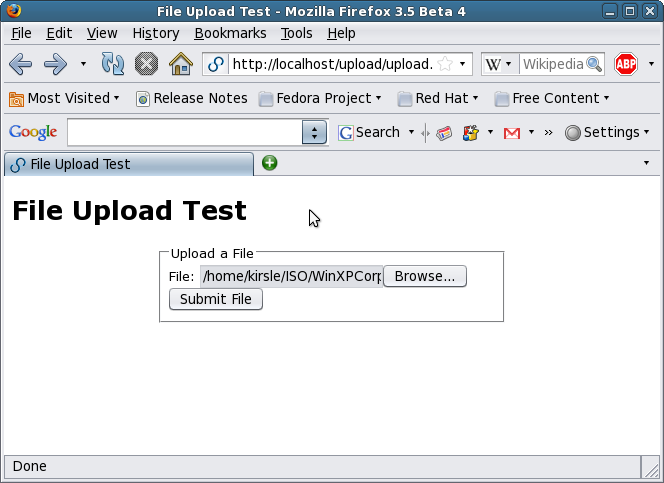 The upload form. Simple.
The upload form. Simple.
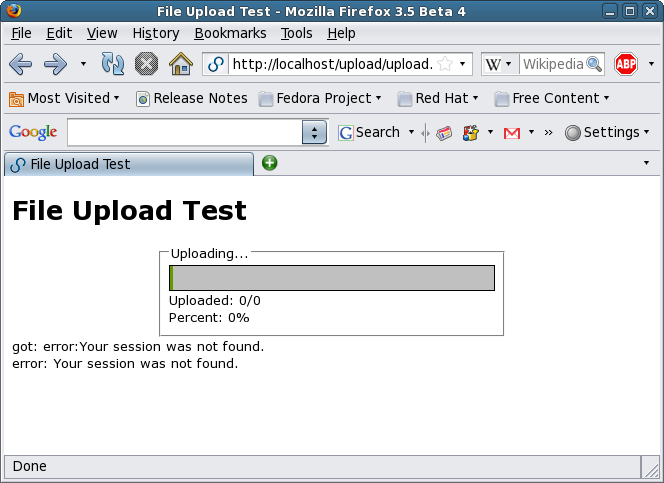 Beginning an upload.
Beginning an upload.
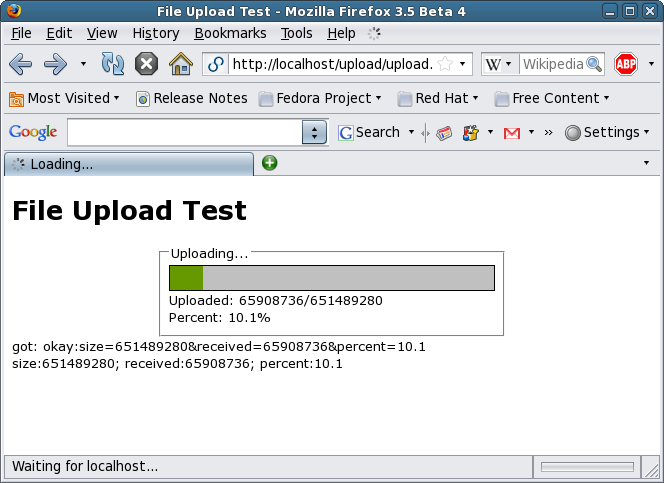 And the progress begins!
And the progress begins!
Source Code:
upload.html (the HTML form and JavaScript)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>File Upload Test</title>
<style type="text/css">
body {
background-color: white;
font-family: Verdana;
font-size: small;
color: black
}
#trough {
background-color: silver;
border: 1px solid black;
height: 24px
}
#bar {
background-color: #669900;
height: 24px;
width: 1%
}
</style>
</head>
<body>
<h1>File Upload Test</h1>
<div id="progress" style="display: none; margin: auto; width: 350px">
<fieldset>
<legend>Uploading...</legend>
<div id="trough"><div id="bar"></div></div>
Uploaded: <span id="uploaded">0</span>/<span id="size">0</span><br>
Percent: <span id="percent">0</span>%
</fieldset>
</div>
<div id="form" style="display: block; margin: auto; width: 350px">
<fieldset>
<legend>Upload a File</legend>
<form name="upload" action="upload.cgi" method="post" enctype="multipart/form-data" onSubmit="return uploadFile(this)">
<input type="hidden" name="action" value="upload">
File: <input type="file" name="file" size="20"><br>
<input type="submit" value="Submit File">
</form>
</fieldset>
</div>
<div id="debug"></div>
<script type="text/javascript">
// When the form is submitted.
function uploadFile(frm) {
// Hide the form.
document.getElementById("form").style.display = "none";
// Show the progress indicator.
document.getElementById("progress").style.display = "block";
// Wait a bit and make ajax requests.
setTimeout("getProgress()", 1000);
return true;
}
// Poll for our progress.
function getProgress() {
var ajax = new XMLHttpRequest();
ajax.onreadystatechange = function() {
if (ajax.readyState == 4) {
gotProgress(ajax.responseText);
}
};
ajax.open("GET", "upload.cgi?action=progress&session=my-session&rand=" + Math.floor(Math.random()*99999), true);
ajax.send(null);
}
// Got an update
function gotProgress(txt) {
document.getElementById("debug").innerHTML = "got: " + txt + "<br>\n";
// Get vars outta it.
var uploaded = 0;
var size = 0;
var percent = 0;
var stat = txt.split(":");
// Was it an error?
if (stat[0] == "error") {
document.getElementById("debug").innerHTML += "error: " + stat[1];
setTimeout("getProgress()", 1000);
return false;
}
// Separate the vars.
var parts = stat[1].split("&");
for (var i = 0; i < parts.length; i++) {
var halves = parts[i].split("=");
if (halves[0] == "received") {
uploaded = halves[1];
}
else if (halves[0] == "percent") {
percent = halves[1];
}
else if (halves[0] == "size") {
size = halves[1];
}
}
document.getElementById("debug").innerHTML += "size:" + size + "; received:" + uploaded + "; percent:" + percent + "<br>\n";
// Update the display.
document.getElementById("bar").style.width = parseInt(percent) + "%";
document.getElementById("uploaded").innerHTML = uploaded;
document.getElementById("size").innerHTML = size;
document.getElementById("percent").innerHTML = percent;
// Set another update.
setTimeout("getProgress()", 1000);
return true;
}
</script>
</body>
</html>
upload.cgi (the CGI script)
#!/usr/bin/perl -w
use strict;
use warnings;
use CGI;
use CGI::Carp qw(fatalsToBrowser);
my $q = new CGI();
# Handle actions.
if ($q->param('action') eq "upload") {
# They just submitted the form and are sending a file.
my $filename = $q->param('file');
my $handle = $q->upload('file');
$filename =~ s/(?:\\|\/)([^\\\/]+)$/$1/g;
# File size.
my $size = (-s $handle);
# This session ID would be randomly generated for real.
my $sessid = 'my-session';
# Create the session file.
open (CREATE, ">./sessions/$sessid") or die "can't create session: $!";
print CREATE "size=$size&file=$filename";
close (CREATE);
# Start receiving the file.
open (FILE, ">./files/$filename");
while (<$handle>) {
print FILE;
}
close (FILE);
# Delete the session.
unlink("./sessions/$sessid");
# Done.
print $q->header();
print "Thank you for your file. <a href=\"files/$filename\">Here it is again</a>.";
}
elsif ($q->param('action') eq "progress") {
# They're checking up on their progress; get their sess ID.
my $sessid = $q->param('session') || 'my-session';
print $q->header(type => 'text/plain');
# Does it exist?
if (!-f "./sessions/$sessid") {
print "error:Your session was not found.";
exit(0);
}
# Read it.
open (READ, "./sessions/$sessid");
my $line = <READ>;
close (READ);
# Get their file size and name.
my ($size,$name) = $line =~ /^size=(\d+)&file=(.+?)$/;
# How much was downloaded?
my $downloaded = -s "./files/$name";
# Calculate a percentage.
my $percent = 0;
if ($size > 0) {
$percent = ($downloaded / $size) * 100;
$percent =~ s/\.(\d)\d+$/.$1/g;
}
# Print some data for the JS.
print "okay:size=$size&received=$downloaded&percent=$percent";
exit(0);
}
else {
die "unknown action";
}
Notes on this code: it's just a proof of concept. You'd want to handle the sessions better. Here the session ID is hard-coded as "my-session" -- that wouldn't work in real life. But it's just a barebones working implementation of a file upload progress bar, with all the crap cut out and does specifically what it's supposed to. Others should find it useful, so you can download it.
Update (11/25/09): This method is all wrong. Here is the correct way.
<a href="/index.cgi?p=blog;tag=General"> as opposed to <a href="/index.cgi?p=blog&tag=General">The reasoning behind it was something along these lines:
&" characters should be fully typed out as "&", because HTML 4.01 no longer allows a single & without any kind of escape sequence following it.
So, http://www.cuvou.com/?p=blog;id=36 looks right in the Google search results, but after it gets chewed up with Google's outgoing statistic gathering and finally accessed by the browser, the latter part of that request comes to my site looking more like this: /?p=blog%3Bid=36. CGI.pm has no idea what to make of this and it can't be blamed. I've tried substituting it in $ENV{QUERY_STRING} before CGI.pm can get its hands on it, but it doesn't help.
So effectively the user is greeted with a "Forbidden" page of mine, which was fired because the value of "p=" contains some invalid character (notably, that % symbol there).
So there's a conundrum here: semicolons as delimiters works as far as CGI is concerned, and it perfectly validates as HTML 4.01 Strict, and you don't need to write "&" all the time inside your internal site links. I mean seriously, how ugly is this HTML code?
<a href="/index.cgi?p=blog&id=36">It validates, it works as expected provided you're using it "properly", however it breaks your links in Google and possibly other search engines, at least in Firefox.
For my CMS, none of my links are "properly" written to begin with. They're like <a href="$link:blog;id=36"> which is translated on-the-fly, so it was fairly trivial to change the code to fix these things on the way out the door.
For the W3C's HTML validator, my links are translated to include the full and proper & text. It's ugly and I'm only glad I don't have to write the links like that directly; my Perl code does it for me.
The other half of the dirty hack is to detect when a troublesome URL has been linked to: particularly if %3B is found. If so, the CGI fixes the query string and sends an HTTP 301 redirect to the proper version of the URL, using the real semicolons (I could replace them with &'s here, but, why? The CGI module takes care of it anyway ;-) ).
I'll have to investigate what other web developers do with their query string delimiters...
Right now, my page doesn't validate as HTML 4.01 Strict, because <script> tags aren't allowed to have a id attribute. What script tag has the ID attribute? The one to display the countdown until Fedora 10's release. If I remove the ID attribute, the script breaks. Nonetheless I'm going to keep it there only for the next three days until Fedora 10 finally arrives, then it's history and next time I want to count down until Fedora 11, I'll find my own implementation instead of pasting their awful HTML code into my otherwise perfect pages.
I've ranted about pasting external code into my site before, so I'll spare you any continued rambling for now. Sometime when I'm more motivated I might follow up on this rant with a sequel.
The moral of the story is, don't give me any code to paste anywhere in anything I have unless the code is completely valid and passes all validation tests (for HTML, that means it passes HTML 4.01 Strict standards).
Speaking of which, I wanted to say a little something about web development. Why have a degree in web design?, some people ask. Any 12-year-old can open Notepad and create a web page. I agree -- and I was that 12-year-old at one point in my life. What separates the men from the boys is the ability to create a web page that validates against the W3C's strictest standards. Yeah, any little kid can throw together a mess of HTML tags and get something out of it. They might even be lucky enough that their page works on every browser. But I've heard enough crying and complaining about how the W3C doesn't validate their page, how they get errors in the triple digits or worse whenever they try to validate their code.
So that's why web development is a skill and not a hobby. With the exception of the Fedora banner (which I highly regret embedding), all my pages on this site and every other site I develop, they all validate HTML 4.01 Strict. Not Transitional -- Strict. That means the W3C doesn't take any shit from my pages whatsoever. And that, my critics, is what sets me apart from the 12-year-olds with Notepad.
0.0026s.
![]()