In this blog post, I'll recount my experience in web development over the last 20 years and how the technology has evolved over time. From my early days of just writing plain old HTML pages, then adding JavaScript to those pages, before moving on to server-side scripts with Perl (CGI, FastCGI and mod_perl), and finally to modern back-end languages like Python, Go and Node.js.
Note that this primarily focused on the back-end side of things, and won't cover all the craziness that has evolved in the front-end space (leading up to React.js, Vue, Webpack, and so on). Plenty has been said elsewhere on the Internet about the evolution of front-end development.
I first started writing websites when I was twelve years old back around the year 1999. HTML 4.0 was a brand new specification and the common back-end languages at the time were Perl, PHP, Coldfusion and Apache Server Side Includes.
This is something I wanted to rant about for a while: event loops in programming.
This post is specifically talking about programming languages that don't have their own built-in async model, and instead left it up to the community to create their own event loop modules instead. And how most of those modules don't get along well with the others.
In an older blog post I mentioned getting Alicebot Program V, a Perl implementation of an Alice AIML bot, up and running on a modern version of Perl, but I didn't go into any details on what I actually did to get this to work (which wasn't very nice of me ;) ).
Unfortunately for me I also didn't even write down any notes for myself, so I had to figure it out again, myself, from scratch. Which I decided to do, only this time I wrote down some notes, and published a new, updated version of Program V which you can check out on GitHub -- or for the lazy, get a zipped release of Program V 0.09.
This blog post is about what I needed to do to get Program V up and running, some of which is also outlined in UpdateNotes.md on the GitHub repo.
pp is the best fully-open-source way to build a stand-alone .exe file from a Perl script, which doesn't require a Perl installation to run). I had installed pp on Windows a long time ago, but the process seems to have changed a bit so here's my experience doing it now, what problems I ran into, and how I fixed them.Versions:
ppm install Win32-Exe.
nmake binary from Microsoft, which replaced the usual make command from Unix. But, it seems Microsoft has pulled this download offline and they want you to install some kind of Visual Studio Express app that provides a newer version of nmake. I ended up finding a copy of nmake somewhere else on the Internet, which I've hosted here: nmake15.zip (NOTE: You might not need nmake, I later found out ActivePerl comes with dmake which worked for installing other modules, YMMV).
The only modules I needed to manually install (perl Makefile.PL; nmake; nmake install) were Module::ScanDeps and PAR::Packer, but running nmake gave this rather cryptic error message:
to undefined at C:/Perl/lib/ExtUtils/Install.pm line 1208I found this relevant Perlmonks article. What I needed to do was open the Makefile (not Makefile.PL; the one with no extension) in Wordpad, and do a Find/Replace of
{{@ARGV}} to {@ARGV}, and then nmake ran just fine.For my project I needed to manually install Template::Toolkit, and the Makefile.PL told me to run dmake. Running this worked just fine without requiring me to manually modify the Makefile. If this is available, I imagine it would probably work better for you then nmake.
Anyway, after installing PAR::Packer's dependencies, PAR::Packer installed and ran just fine.
I decided to keep things simple, and went with a plain text, ASCII based file format for the Tyd archives. Originally I was planning to make it a binary file format, but I didn't wanna have to deal with C-style data types (which would probably end up imposing limits on me, for example a 32-bit number has a maximum value of about 4 billion, which caused problems with the FAT32 file system by limiting maximum file sizes to 4 GB). So, plain text keeps things much simpler.
First, I'll show you what an example Tyd2 archive looks like:
TYD2:SHA1:46698a6530d53ca7004719bcad5095efaa09420a [header] name=Untitled Archive packager=Archive::Tyd/2.00 [file:/file1.txt] asize=68 atime=1345597264 checksum=97503ea37402b56b429c5210e9cfcd843c38b486 chmod=33204 ctime=1345597264 index=0 mtime=1345597264 size=51 [file:/file3.txt] asize=32 atime=1345597264 checksum=37c9daa7930605795dbc00753e7d93c0da50b9e5 chmod=33204 ctime=1345597264 index=1 mtime=1345597264 size=24 [content] VGhpcyBpcyBmaWxlIG51bWJlciBvbmUuCgpJdCBpcyBhIHZlcnkgc21hbGwgZmlsZS4K VGhpcwppcwp0aGUKdGhpcmQKZmlsZS4KThe archive resembles an INI file in some ways. The very first line begins with "TYD2" as a sort of magic number for the file format, and then the checksum algorithm that's being used throughout the entire archive (SHA1 in this case), and then the SHA1 checksum of the entire archive itself (this is, the checksum of the entire file after the first line). This way the archive can easily self-validate.
Then we have the [header] section, with archive headers. Tyd 2.0 supports pluggable "file mangling algorithms" which will let you compress or encrypt the file contents in any way that you want. If an algorithm is being used, one of the headers will be "algorithm" and will name the algorithm being used; for example, "algorithm=CipherSaber". In this example, no algorithm is used.
Then there are [file:*] sections. There's one for each file in the archive. Each file contains a handful of attributes, like their creation and modification times, chmod permissions, file size and "archive size" (the size of the Base64-encoded data in the archive itself), and most importantly, an index number. This is how Archive::Tyd is able to "pluck" the file's data out of the [content] section.
In the [content] section lies the Base64-encoded data that belongs to each file mentioned in the file table, with one on each line. So, for the file whose index is "0", the very first line after the [content] section belongs to that file. The file with index "1" has the second line, and so on.
When an algorithm is used to mangle the file data, the data gets mangled before being encoded in Base64. So, for example, if you use CipherSaber to password-encrypt your file data, their data is encrypted and then encoded to Base64 (so you can't simply Base64-decode the data; you'd still have to decrypt the result with the CipherSaber password that was used).
You could just as well create a compression algorithm to use for this, for example something that uses Compress::Deflate7, but I'm not sure how useful compression will be considering the Tyd file format itself is kind of bloated (since it's ASCII based and not binary). But to each their own.
Anyway, this project is still in development. I plan to at least work out a way to get RSA encryption and signing to work before I release this module to CPAN. One idea I have for RSA signatures would be:
There would be support for custom blocks in the file, so you could create a [signature] block to hold the RSA signature, and a method to get the entire file table as a string. So, you could create your archive, get the file table out of it, cryptographically sign the table using your RSA private key, and then include the resulting signature directly inside the Tyd archive itself.
Also, I have yet to think up a way to support encrypting the file table itself, in cases where the file names and attributes are to be considered sensitive information as well.
Stay tuned.
You can check out the progress so far on GitHub: https://github.com/kirsle/Archive-Tyd.
I took a fresh look at trying to wrangle Tkx into working on the standard Perl distribution.
Tkx is ActiveState's module that provides a modern, updated Tk framework for Perl. I previously wrote about how the old Tk module for Perl has been neglected for many years and is extremely outdated and has very little hope for being improved on. Tkx brings a more updated Tk interface to Perl.
The only problem is, it only really runs well on ActivePerl, and not the stock version of Perl. I've been testing Tkx over the years on various versions of Fedora Linux and Perl, and every time I'd get the same results: segmentation faults. It was impossible to run any code that uses the Tkx module, because attempting to do so much as use Tkx; would cause a segfault. I chalked it up to "it only works with ActivePerl" and left it alone. But now I decided to give it another go.
I was seeing the same symptoms this time as before. When trying to install it with cpan or cpanm, it would fail to install because its test suite was failing (giving errors like, can't find package tk). If I installed it while skipping the test suite, the tkx-ed example program would give segfaults when run. Just as before.
I found out through tinkering with it that I needed to yum install tk (it makes sense; Tkx is a wrapper around Tcl/Tk for Perl, so you need "the" Tk installed for it to work). With this, running make test would have it run through the test suite and I'd see all the graphical Tk windows pop up and disappear. But running tkx-ed would still give segfaults.
I believe I'd gotten to this point before. The test suite would work, but nothing else would. So I decided to try running the test suite "by hand", perl t/LabEntry.t. Segmentation fault. What? How can the test suite run all these scripts successfully but I can't run them myself? So, I dissected the Makefile that was used for the test suite.
Long story short, this doesn't work:
[kirsle@fireworks Tkx-1.09]$ perl tkx-ed
Segmentation fault (core dumped)
But this does:
[kirsle@fireworks Tkx-1.09]$ PERL_DL_NONLAZY=1 perl tkx-ed
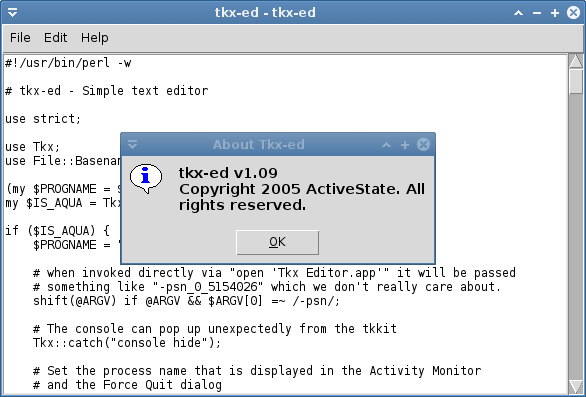
Shazam. This is tkx-ed running on a stock version of Perl 5.14.2 on Fedora 17. It seems that the PERL_DL_NONLAZY environment variable is required for the Tkx module to work. This is weird.
I don't call this a victory though. Requiring this environment variable to be set for your Tkx app to run isn't very ideal. If you wrote and distributed a Tkx app for Linux users, you'd require the users to run a Bash shell script in order to launch your program instead of just running your Perl program directly like they'd expect. But, at least it works!
Note: I also needed to
yum install bwidgetbecause tkx-ed would give a "can't find package BWidget" error without it).
Update (6/24/12):
As for that environment variable issue, I found that this will work:
#!/usr/bin/perl
BEGIN {
$ENV{PERL_DL_NONLAZY} = 1;
}
use 5.14.0;
use strict;
use warnings;
use Tkx;
...
Since your BEGIN block gets run before Perl attempts to load the modules, you can set the variable inside your script. And now a simple perl yourscript.pl will work without segfaults. :)
I decided to take a serious look at the HTML::Defang module. It's supposed to take some arbitrary HTML input and sanitize it, removing anything potentially malicious in the process (attempts to execute JavaScript code, embedding of iframes, applets, etc.)
It does a pretty decent job, but I found one thing it doesn't handle very well by default. In CSS code, it will attempt to comment out an attribute if you attempt to use JavaScript with it. Some example input:
<span style="background-image: url('javascript:alert(1)')">
HTML::Defang will turn that into this:
<span style="/*background-image: url('javascript:alert(1)')*/">
But, if you begin and end your CSS attribute with an end-comment and start-comment instead, HTML::Defang leaves the code looking like this:
<span style="/**/background-image: url('javascript:alert(1)')/**/">
Now, granted, this sort of exploit only really hits Internet Explorer users (at least for older versions of IE), but it is a pretty big issue still. This is basically how Samy pwned MySpace, after all.
Anyway, I've written a test CGI script for HTML::Defang: you can try to break it here. I added a custom CSS handler that will neutralize JavaScript attempts from the CSS code to handle that problem I found in HTML::Defang. You can see the source code by clicking the link at the bottom of that page.
If anybody finds a way to get JavaScript to execute on that page, let me know. :) I've tried all the usual tricks and haven't found a loophole yet.
XMPP Gateways (or, alternately, Transports) are services for XMPP that let users sign on to other instant messaging networks (AIM, MSN, YMSG, etc.) through their XMPP account. So... you sign in to XMPP and the server signs you in to your other networks, and you can do all your chatting through just the one XMPP connection (Wikipedia has a nice diagram of this).
So I was wondering whether this would be a good solution for programming chatbots that work on many different IM networks. In Perl, the options for IM network connectivity aren't all that great at the moment; there is Net::OSCAR for AIM, Net::XMPP, and that's about it. Matt Austin and I were working on Net::IM::YMSG for Yahoo Messenger, but it's not that great yet (it can chat and accept add requests, but after accepting you don't see it online until the program restarts). For MSN Messenger, there's a dusty old MSN.pm module somewhere on the RiveScript forums that might still work but hasn't been updated in years.
I'm not very motivated to work more on Net::IM::YMSG because YMSG is dead to me. I created a new Yahoo ID recently, and made sure to opt-out of any directory listings, and it still gets add requests by spam bots on a regular basis. The ID is literally listed nowhere. I don't know how they find me. It is my opinion that nobody should take YMSG seriously anymore. I don't know anybody who uses it, so developing new code to use YMSG isn't worth my time.
With XMPP gateways though, one could just write an XMPP bot and let the gateways do all the work. Then you can have a bot sign on to AIM, Yahoo, MSN, ICQ, IRC, and even some obscure networks like MySpace IM, without needing to use native libraries for each protocol yourself. Sounds great, but I had some questions about how well gateways work (how many features they support per network, etc.)... so the best way to find out was to test it!
I installed the Openfire XMPP Server on my web server. Installation was surprisingly super easy. Basically all I had to do was this:
# apt-get install sun-java6-jre # dpkg -i openfire_3.7.1_all.deb
This installed it and automatically started it, and then I went to the admin panel port on my server to set it up. I didn't have to touch any config files or anything; everything was done through the web panel and was dead simple. I set up a Jabber user @kirsle.net and then I went out in search of a gateway plugin.
I found Kraken to fill the role. Installing this plugin was super ridiculously simple too, I just copied kraken.jar to /usr/share/openfire/plugins and Openfire automatically saw it and extracted it and a new "Gateways" tab appeared in the web panel. Black magic. I later discovered that I could've just uploaded kraken.jar to a file upload field on the Plugins page on the web panel, too. This is, by far, the easiest server software for Linux that I've ever seen. I can't believe Openfire is free and open source.
So after setting the gateways up for the protocols that I care about, here is what I found:
For simple chatbots that only need to communicate over IM, XMPP gateways should work out fine. But if you have a native way to connect to a particular network, that method would most surely be preferred.
The reason I like the @aim.kirsle.net etc. suffixes on gateway usernames is because it would make it easier for a chatbot to distinguish unique users across multiple networks. In my Aires bot (which supports AIM and YMSG, through Net::IM::YMSG), and in all my older bots from years gone by, the protocol-facing code would format a user's name like "AIM-kirsle" or "YMSG-kirsle" before passing it to the main bot code. This way I could make an AIM user an admin for my bot, without any confusion about overlapping Yahoo IDs of the same name. Since the XMPP transports make a unique subdomain for each network, this can be used instead.
In conclusion, I think it will be worth it to add XMPP support to my Aires bot so that transports can be used for people who want them. Native support for a network is always preferred, but with transports you can easily put your bot on a lot more networks with very little effort.
Update (5/28/13): I've ported this script over to Python: pyupdatesd. The Python version only requires pygtk2, which tends to come preinstalled on Fedora XFCE systems.
Since about three versions of Fedora ago, there wasn't an updates daemon for the XFCE desktop environment (or LXDE or the others, for that matter). KDE still had theirs, and Gnome 3's update daemon was built in to the desktop environment. So, XFCE users were stuck having to look for updates manually.
Not anymore!
I finally got around to writing a Perl script that checks for available updates, and shows a Gtk2 tray icon and a notification pop-up when one has been found. You can set it to start up automatically in your session settings and it will check updates for you every 15 minutes.
You can get it from http://sh.kirsle.net/kupdatesd. Or you can see its source code here. :)
#!/usr/bin/perl
# kupdatesd - A simple yum update checker.
#
# This script will watch for available yum updates and show a GTK+ TrayIcon
# and notification pop-up when updates become available.
#
# This is intended for desktop environments like XFCE that don't have a native
# PackageKit update watcher.
#
# Set this script to run on session startup and it will check for updates every
# 5 minutes (by default; this is configurable in the source code).
#
# --Kirsle
# http://sh.kirsle.net
use 5.14.0;
use strict;
use warnings;
use Gtk2 -init;
use Gtk2::TrayIcon;
use Gtk2::Notify -init, "kupdatesd";
################################################################################
# Configuration Section #
################################################################################
my %c = (
# The title to be shown on the pop-up and the icon tooltip.
title => "Updates Available",
# The message to be shown in the pop-up.
message => "There are updates ready to install.",
# The icon to use for the pop-up and tray icon.
icon => '/usr/share/icons/gnome/32x32/status/software-update-available.png',
# How often to check for updates (in seconds).
interval => 900,
# The path to your yum binary.
yum => '/usr/bin/yum',
# The path to your graphical updater.
# gpk-update-viewer is provided by gnome-packagekit
gui => '/usr/bin/gpk-update-viewer',
);
################################################################################
# End Configuration Section #
################################################################################
# Gtk objects
my ($icon, $image, $eventbox, $tooltip, $notify);
my $visible = 0; # Icon is currently being displayed?
# Enter the main loop.
my $check = time() + $c{interval};
while (1) {
select(undef,undef,undef,0.1);
# Keep Gtk2 active.
if (defined $icon) {
Gtk2->main_iteration while Gtk2->events_pending;
}
if (time() > $check) {
# Look for updates.
unless ($visible) {
system("$c{yum} check-update > /dev/null 2>&1");
if ($? >> 8 == 100) {
say "There are updates available!";
show_icon();
}
}
# Queue another check.
$check = time() + $c{interval};
}
}
sub show_icon {
# Already initialized this once before?
if (defined $icon) {
# Just show the icon and notification again.
$icon->show_all;
$notify->show;
$visible = 1;
return;
}
# Tray icon. Image goes in EventBox, EventBox goes inside TrayIcon.
$icon = Gtk2::TrayIcon->new("kupdatesd");
$image = Gtk2::Image->new_from_file($c{icon});
$eventbox = Gtk2::EventBox->new;
$eventbox->add($image);
$icon->add($eventbox);
$icon->show_all;
# Attach the tooltip.
$tooltip = Gtk2::Tooltips->new;
$tooltip->set_tip($icon, $c{title});
$eventbox->signal_connect("button_press_event", sub {
$icon->hide;
$visible = 0;
system($c{gui});
});
$notify = Gtk2::Notify->new(
$c{title},
$c{message},
$c{icon},
);
$notify->show;
$visible = 1;
}
If anyone's interested, I wrote a Perl script that downloads and installs Firefox Nightly on a Unix-like operating system.
By default, it installs the application into /opt/firefox-nightly, with a link to run it at /usr/bin/firefox-nightly. This way, it doesn't conflict with your already-installed version of Firefox. Furthermore, it will put a launcher item in your Applications/Internet menu.
You can get it from here: http://sh.kirsle.net/ffnightly
$ mkdir ~/bin
$ wget http://sh.kirsle.net/ffnightly -O bin/ffnightly
$ chmod +x bin/ffnightly
$ ffnightly
0.0021s.
![]()
{kind=link}