I blog about anything I find interesting, and since I have a lot of varied interests, my blog entries are kind of all over the place. You can browse my tags to sort them by topic and see which ones I frequently write about, or the archive has a complete history of my posts, dating back to 2008!
Besides my blog, I have pages for my creative projects, which are linked to on the navigation bar.
I write a lot about Linux and Android, Minecraft, and I like to rant about stuff. Generally anything that makes me curious. Also check out my Bookmarks for all sorts of cool websites about various topics I'm interested in.
For the geeks: this website respects your privacy and doesn't run any third party ads or analytics. This site speaks HTTP and doesn't require any JavaScript to work.
Bing still isn't better than Windows Live searchLinks for simple search terms, such as "picture", or "blog", or "Linux"...
From URLs that indicated the link came from the very first page of search results that Windows Live provided for those simple, generic, single-word search queries.
Thusly I concluded that Windows Live Search is complete crap, and is probably powered by a primitive SQL query that has no regard at all for relevance, no "page rank" technology, and otherwise nothing at all that determines what results are the "best" ones to show to the user. Google would never let such things fly. Getting a link to my site because you searched for the word "picture", and one or two pages on my site might've used the word in passing? That's a big FAIL.
So, now that Bing is out, and it's all over the news and Digg about how great it is and how it's (finally) a competitor for Google, I was hoping that if I got any links in from Bing searches, that they'd be from more useful search queries.
I was wrong!
I was just looking at my incoming referrers, and somebody who did an Images search for "Acer Aspire" linked to my site (this page, specifically)... from the first page of results. I had to check this out. Sure enough, the 10th image that comes up for that query is the picture of an Acer Aspire 5050 laptop that I included on that page.
The 10th result. Is my site about the Acer Aspire at all? About laptops period, even? Why, when there's SO many other sites out there that are more relevant, would my site come up in the top 10 results? It's broken. As usual.
Microsoft should just give up on the search scene altogether. MSN Search, Windows Live Search, Bing... no matter what they call it, it's the same exact failure of a search engine. Hopefully they'll learn their lesson after this and not try again with yet another search engine in the next couple years and just give up completely.
For the most relevant results for your search queries, Google is still the best.
Just edit your .bashrc file and add this function to it:
# Allow the user to set the title.
function title {
PROMPT_COMMAND="echo -ne \"\033]0;$1 (on $HOSTNAME)\007\""
}
Now you can just do e.g. title IRC or whatever, and it would set the window title to IRC (on aerelon) if your hostname was aerelon like mine is (the hostname is handy if you work with multiple servers).Now, the original post follows:
This is a small script I wrote that allows you to set a custom window title on your bash shells. It works in most sane bash terminal emulators (gnome-terminal and XFCE's Terminal for sure, Konsole likely, xterm likely...)
It works kinda, sorta like the DOS `title` command, except it doesn't take your title on the command line and instead prompts for it after you run the command.
Installation is in 2 parts:
1) The bash script, which you put in your home directory's "bin" folder (eg /home/kirsle/bin) - make the folder if it doesn't exist.
#!/bin/bash echo -n "Title: " read -e TITLE PROMPT_COMMAND='echo -ne "\033]0;$TITLE\007"'2) The bash alias. Setting a title manually involves typing that last line (PROMPT_COMMAND) into the terminal directly (with an actual title in place of $TITLE); it sets the environment variable PROMPT_COMMAND, which ensures your custom title sticks. Bash scripts aren't allowed to modify your environment variables by default. So, set an alias to this command that, instead of executing it, sources it instead.
Edit your .bashrc file (eg. /home/kirsle/.bashrc):
alias title='. /home/kirsle/bin/title'Now reload your .bashrc file with the command `. ~/.bashrc` or start a new bash shell, type in the word `title` and hit enter, and enter a title when prompted.
Update (11/25/09): This method is all wrong. Here is the correct way.
A thread on Tek-Tips came up recently about making a progress bar for a file uploader in Perl.
Investigating the issue more closely, I found a couple of commercial solutions (read: paid for), where even their free edition involves thousands upon thousands of lines of code, spread out across many different files. Nowhere to be found was a simple, straight-to-the-point example of how this could be done.
From poking around at what code I could find, I got the basic gist to it:
It looks like this:
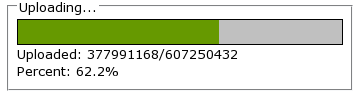
If that sounds complicated, it really isn't. 77 lines for the CGI script, and 126 lines for the HTML page, including the JavaScript (only 60 lines of JavaScript).
The screenshots, code, and download link follow.
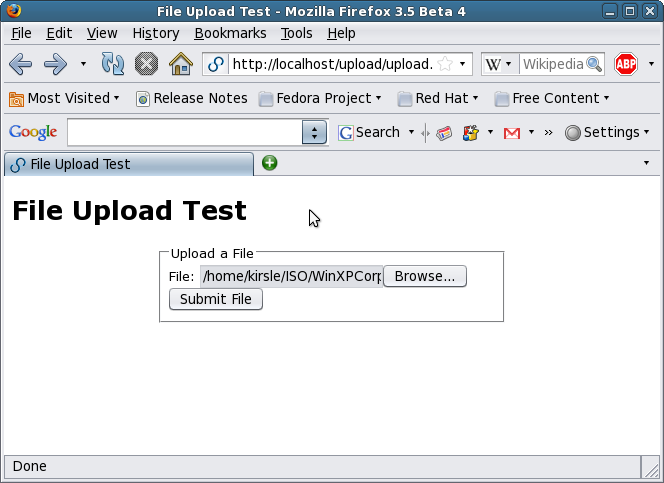 The upload form. Simple.
The upload form. Simple.
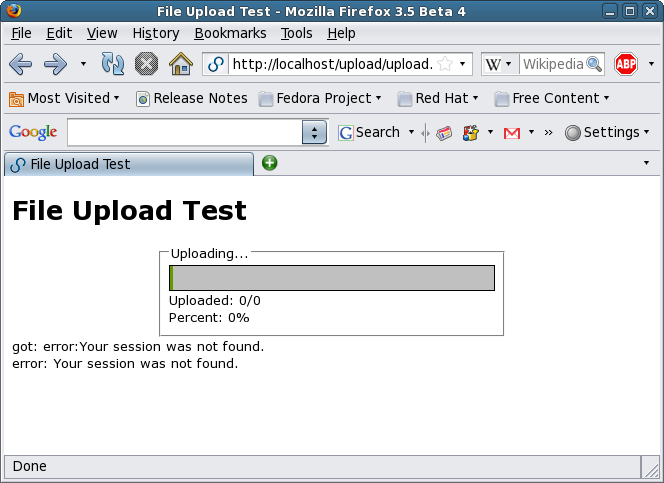 Beginning an upload.
Beginning an upload.
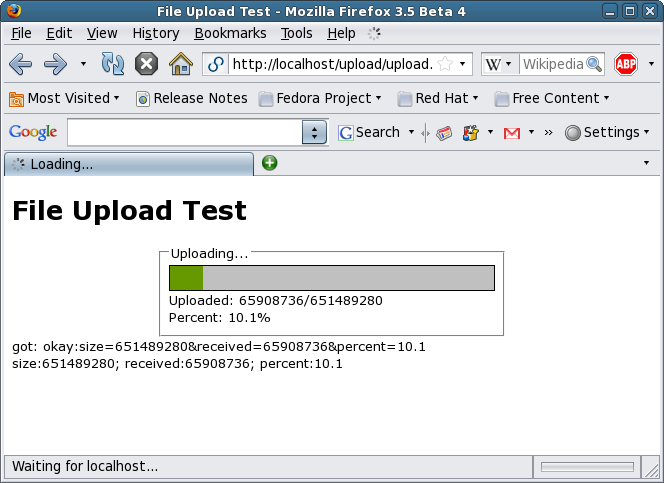 And the progress begins!
And the progress begins!
Source Code:
upload.html (the HTML form and JavaScript)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>File Upload Test</title>
<style type="text/css">
body {
background-color: white;
font-family: Verdana;
font-size: small;
color: black
}
#trough {
background-color: silver;
border: 1px solid black;
height: 24px
}
#bar {
background-color: #669900;
height: 24px;
width: 1%
}
</style>
</head>
<body>
<h1>File Upload Test</h1>
<div id="progress" style="display: none; margin: auto; width: 350px">
<fieldset>
<legend>Uploading...</legend>
<div id="trough"><div id="bar"></div></div>
Uploaded: <span id="uploaded">0</span>/<span id="size">0</span><br>
Percent: <span id="percent">0</span>%
</fieldset>
</div>
<div id="form" style="display: block; margin: auto; width: 350px">
<fieldset>
<legend>Upload a File</legend>
<form name="upload" action="upload.cgi" method="post" enctype="multipart/form-data" onSubmit="return uploadFile(this)">
<input type="hidden" name="action" value="upload">
File: <input type="file" name="file" size="20"><br>
<input type="submit" value="Submit File">
</form>
</fieldset>
</div>
<div id="debug"></div>
<script type="text/javascript">
// When the form is submitted.
function uploadFile(frm) {
// Hide the form.
document.getElementById("form").style.display = "none";
// Show the progress indicator.
document.getElementById("progress").style.display = "block";
// Wait a bit and make ajax requests.
setTimeout("getProgress()", 1000);
return true;
}
// Poll for our progress.
function getProgress() {
var ajax = new XMLHttpRequest();
ajax.onreadystatechange = function() {
if (ajax.readyState == 4) {
gotProgress(ajax.responseText);
}
};
ajax.open("GET", "upload.cgi?action=progress&session=my-session&rand=" + Math.floor(Math.random()*99999), true);
ajax.send(null);
}
// Got an update
function gotProgress(txt) {
document.getElementById("debug").innerHTML = "got: " + txt + "<br>\n";
// Get vars outta it.
var uploaded = 0;
var size = 0;
var percent = 0;
var stat = txt.split(":");
// Was it an error?
if (stat[0] == "error") {
document.getElementById("debug").innerHTML += "error: " + stat[1];
setTimeout("getProgress()", 1000);
return false;
}
// Separate the vars.
var parts = stat[1].split("&");
for (var i = 0; i < parts.length; i++) {
var halves = parts[i].split("=");
if (halves[0] == "received") {
uploaded = halves[1];
}
else if (halves[0] == "percent") {
percent = halves[1];
}
else if (halves[0] == "size") {
size = halves[1];
}
}
document.getElementById("debug").innerHTML += "size:" + size + "; received:" + uploaded + "; percent:" + percent + "<br>\n";
// Update the display.
document.getElementById("bar").style.width = parseInt(percent) + "%";
document.getElementById("uploaded").innerHTML = uploaded;
document.getElementById("size").innerHTML = size;
document.getElementById("percent").innerHTML = percent;
// Set another update.
setTimeout("getProgress()", 1000);
return true;
}
</script>
</body>
</html>
upload.cgi (the CGI script)
#!/usr/bin/perl -w
use strict;
use warnings;
use CGI;
use CGI::Carp qw(fatalsToBrowser);
my $q = new CGI();
# Handle actions.
if ($q->param('action') eq "upload") {
# They just submitted the form and are sending a file.
my $filename = $q->param('file');
my $handle = $q->upload('file');
$filename =~ s/(?:\\|\/)([^\\\/]+)$/$1/g;
# File size.
my $size = (-s $handle);
# This session ID would be randomly generated for real.
my $sessid = 'my-session';
# Create the session file.
open (CREATE, ">./sessions/$sessid") or die "can't create session: $!";
print CREATE "size=$size&file=$filename";
close (CREATE);
# Start receiving the file.
open (FILE, ">./files/$filename");
while (<$handle>) {
print FILE;
}
close (FILE);
# Delete the session.
unlink("./sessions/$sessid");
# Done.
print $q->header();
print "Thank you for your file. <a href=\"files/$filename\">Here it is again</a>.";
}
elsif ($q->param('action') eq "progress") {
# They're checking up on their progress; get their sess ID.
my $sessid = $q->param('session') || 'my-session';
print $q->header(type => 'text/plain');
# Does it exist?
if (!-f "./sessions/$sessid") {
print "error:Your session was not found.";
exit(0);
}
# Read it.
open (READ, "./sessions/$sessid");
my $line = <READ>;
close (READ);
# Get their file size and name.
my ($size,$name) = $line =~ /^size=(\d+)&file=(.+?)$/;
# How much was downloaded?
my $downloaded = -s "./files/$name";
# Calculate a percentage.
my $percent = 0;
if ($size > 0) {
$percent = ($downloaded / $size) * 100;
$percent =~ s/\.(\d)\d+$/.$1/g;
}
# Print some data for the JS.
print "okay:size=$size&received=$downloaded&percent=$percent";
exit(0);
}
else {
die "unknown action";
}
Notes on this code: it's just a proof of concept. You'd want to handle the sessions better. Here the session ID is hard-coded as "my-session" -- that wouldn't work in real life. But it's just a barebones working implementation of a file upload progress bar, with all the crap cut out and does specifically what it's supposed to. Others should find it useful, so you can download it.
Update (11/25/09): This method is all wrong. Here is the correct way.
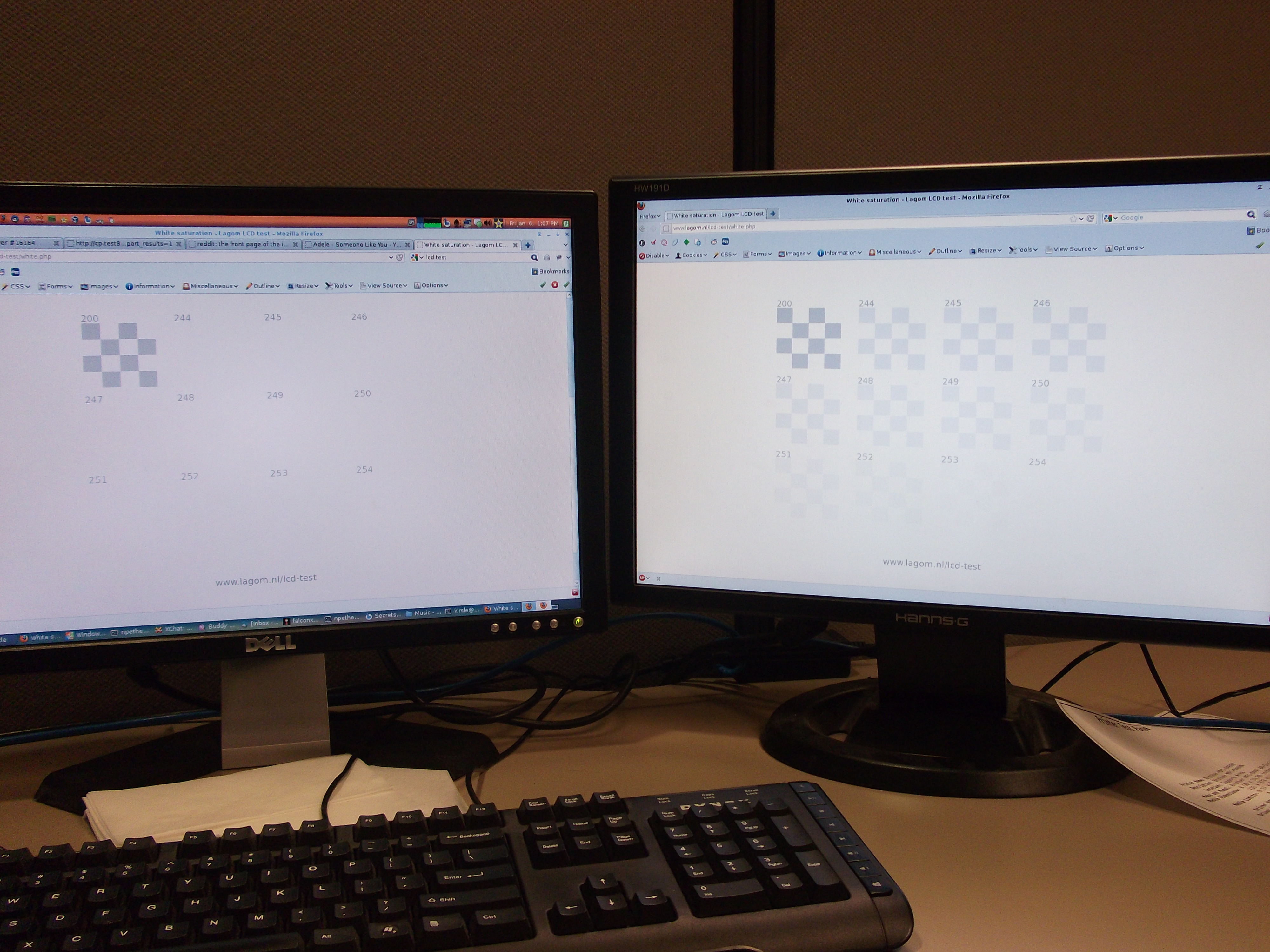
I compared the settings between this monitor and the Hanns-G... the Hanns-G has 100 for brightness/contrast and for R/G/B; the Dell has 67 for brightness/contrast, and maxing them out whitewashes the entire image and makes the contrast even more horrible. So I'm at the conclusion that probably all Dell monitors have this issue, so I don't think I'll ever buy one for personal use.
Here is a new picture of an LCD monitor test page viewed on both monitors simultaneously. It very clearly shows the difference, and no, the Dell monitor can't be reconfigured to show the contrast correctly. dell-white.jpg (caution: 4000x3000 pixel resolution).
Now the original blog post follows.
Here's a rant I've been wanting to go on about the Dell E176FP LCD monitors.
These monitors suck!
My college used these monitors everywhere, because they bulk ordered cookie-cutter Dell machines to use as every workstation in every lab in the entire campus. And all of these monitors were just terrible.
I first realized how terrible they are at campus because the brightness on every monitor was set very dark, and this annoyed me. But I couldn't do much about it. Yes, the brightness and contrast was only at 75%, but if I upped those, the screen would become "too" bright -- everything would be white-washed. Subtle changes in gray, such as the status bar on Firefox compared to the white background of a web page, would blend together and there would be no distinguishable separation at all. And, if the Windows machine happened to have the Classic skin, you couldn't tell where status bars ended and the task bar begins.
A white-washed monitor is not usable by any stretch of the imagination.
And then, the monitor I had at my workstation at the office was one of these terrible Dell monitors. Fortunately, I didn't have to deal with it for very long, because all the engineers soon got NVIDIA cards and second monitors, to make us work more efficiently. These new monitors were Hanns-G, 1440x900 pixel LCDs.
I run Linux at my workstation, and with the second monitor, I decided that I'd run a virtual Windows XP machine full-screen in one monitor, and keep the other monitor dedicated to Linux for development. I chose the new Hanns-G monitor to run the Linux half, and the Dell monitor to run the Windows half.
I still kept noticing the color quality differences in the monitors, though. I'd use Windows almost exclusively to test our front-end web product, but every now and then I'd also test it in Linux. On the Hanns-G monitor, the web pages were so bright and colorful, compared to on the Dell monitor. It was like taking off your sunglasses after wearing them for half the day and being amazed how bright the world is.
But this still wasn't too bad.
Some time later, I configured Linux in an interesting way on my laptop, having it run the GNOME desktop environment but use XFCE's window manager. I had all kinds of semi-transparency effects on it, like having the menus be see-through as well as the window decorations. I took a screenshot to send to one of my friends, and I previewed this screenshot in Windows on this crappy Dell monitor, and this is where I officially started to hate this monitor.

The Dell monitor, being SO terrible with color quality, was NOT able to display the transparency in the popup menu there! The menu was probably 10% transparent. Now mind you, this is a screenshot. I wasn't asking the monitor to render semi-transparency. It only had to display what had already been rendered. And it failed!
The menu bar has a solid gray background, not transparent at all. The panel and window borders were still see-through, because I gave them higher transparency levels, but even then the panel looks a bit more milky-white on the Dell monitor.
So, I swapped the monitors; now Linux uses the crappy color-challenged Dell monitor, since I primarily use the Linux half for development in text-based terminals, and the Windows half gets the Hanns-G monitor where I can see everything in their full colors.
Since the monitor has nothing to do with how the colors actually are to the computer, I couldn't just take a screenshot to show you the difference. So, on the Hanns-G monitor, I opened the screenshot in Photoshop and applied +20 contrast to it, which made it look pretty darn close to the same screenshot viewed on the Dell monitor.
Here are links to the full-size PNG screenshots, so you can see all the differences yourself. Note that if you have such a Dell monitor, and these screenshots look pretty much exactly the same, you're verifying my point. These Dell monitors are crap!
</rant>
And today is one such day that I tried to SSH home and got a "Connection refused", because my IP had changed. My bot told me what my new address was, and all was good.
Which brings me to my next point: the program I wrote for my bots I named AiRS (Artificial Intelligence: RiveScript). If any of my readers know me from when I used to run AiChaos.com, this bot is sort of like my Juggernaut and Leviathan programs. The bot can run multiple connections (mirrors) to multiple listeners (so far, AIM and HTTP, but I'll be adding MSN Messenger support shortly). Unlike Juggernaut and Leviathan, though, the program uses RiveScript and RiveScript only as the reply engine.
By the time I release the program it will definitely have support for AIM, MSN, IRC, and HTTP. Other listeners? Maybe, maybe not. Jabber is a possibility. It will depend on what existing modules are available, how usable they are, how well they work, etc.
At any rate, you can chat with my AIM bot by sending an IM to AiRS Aiden. So far it just chats, but it can also tell you how the weather is, play mad libs, and do a couple less cool things.
<a href="/index.cgi?p=blog;tag=General"> as opposed to <a href="/index.cgi?p=blog&tag=General">The reasoning behind it was something along these lines:
&" characters should be fully typed out as "&", because HTML 4.01 no longer allows a single & without any kind of escape sequence following it.
So, http://www.cuvou.com/?p=blog;id=36 looks right in the Google search results, but after it gets chewed up with Google's outgoing statistic gathering and finally accessed by the browser, the latter part of that request comes to my site looking more like this: /?p=blog%3Bid=36. CGI.pm has no idea what to make of this and it can't be blamed. I've tried substituting it in $ENV{QUERY_STRING} before CGI.pm can get its hands on it, but it doesn't help.
So effectively the user is greeted with a "Forbidden" page of mine, which was fired because the value of "p=" contains some invalid character (notably, that % symbol there).
So there's a conundrum here: semicolons as delimiters works as far as CGI is concerned, and it perfectly validates as HTML 4.01 Strict, and you don't need to write "&" all the time inside your internal site links. I mean seriously, how ugly is this HTML code?
<a href="/index.cgi?p=blog&id=36">It validates, it works as expected provided you're using it "properly", however it breaks your links in Google and possibly other search engines, at least in Firefox.
For my CMS, none of my links are "properly" written to begin with. They're like <a href="$link:blog;id=36"> which is translated on-the-fly, so it was fairly trivial to change the code to fix these things on the way out the door.
For the W3C's HTML validator, my links are translated to include the full and proper & text. It's ugly and I'm only glad I don't have to write the links like that directly; my Perl code does it for me.
The other half of the dirty hack is to detect when a troublesome URL has been linked to: particularly if %3B is found. If so, the CGI fixes the query string and sends an HTTP 301 redirect to the proper version of the URL, using the real semicolons (I could replace them with &'s here, but, why? The CGI module takes care of it anyway ;-) ).
I'll have to investigate what other web developers do with their query string delimiters...
yumdownloader --source packagenameThat will fetch the source RPM for the package. For instance
yumdownloader --source firefox downloads firefox-3.0.8-1.fc10.src.rpm on my Fedora 10 system.The source RPM can be opened with an archive manager and extracted. You can then tinker with it and rebuild a custom new RPM, for instance if you want Apache to be compiled with suexec support built in, which doesn't come standard in any RedHat distro I've ever used.
Note: if you don't have yumdownloader installed, it's part of the yum-utils package. yum install yum-utils.
I've just discovered a program called Console. It's a command prompt replacement for Windows, and is much more like a Linux terminal emulator. Not quite gnome-terminal, but much better than cmd.exe:
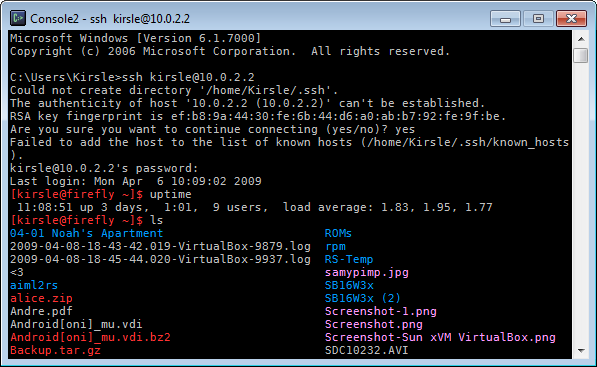
Why it's so much better than command prompt:
I also recommend OpenSSH for Windows. It installs OpenSSH from the Cygwin project, without the entire Cygwin installation (which is enormous, and is overkill if all you want is SSH from it). With this you can open a command prompt or Console window and use SSH as though you were on a Linux system.
These two programs are all I need to feel more at home when I have to use a Windows system. :)
 One of my interests concerning video games is to see what happens when you tweak a game to do something the developers hadn't intended. In some cases the game crashes, and in others a lot is revealed about how aspects of the game were programmed.
One of my interests concerning video games is to see what happens when you tweak a game to do something the developers hadn't intended. In some cases the game crashes, and in others a lot is revealed about how aspects of the game were programmed.One of the games that I've done more than a little bit of poking around at is The Legend of Zelda: Ocarina of Time for the Nintendo 64. One particularly interesting part of the game is the battle against Dark Link during the quest through the Water Temple. A typical battle with Dark Link plays out like this video on YouTube, uploaded by mtiller2006.
Dark Link's usual behavior in the Water Temple is to wait until you've gone to the opposite end of the room before even appearing. Then it just waits for you to get close to it, or target it, or try to attack it from a distance before it springs into life. It runs away if you get too close to it, and comes toward you if you get too far away. Dark Link isn't aggressive to begin with, but with enough time or enough prodding by the player, it begins trying to kick your ass.
Normal sword swipes get canceled out by Dark Link's sword swipes. Stab at Dark Link and he jumps up on top of your sword (and if he's feeling aggressive, he'll slash at you from up there too before jumping off). When attacked, he suffers damage, falls through the floor and then respawns, usually behind you.
Besides that, though, Dark Link's role is pretty simple. You battle him inside a boring square room. All Dark Link needs to do is walk around and use his sword, and do a couple of his own moves that the player can't do, such as standing on top of the other one's sword.
When placed in the Kokiri Forest by using actor replacement cheat codes, you see how Dark Link behaves when put into a room he wasn't intended to be put into. His home in the Water Temple is a simple, empty room, but in the Kokiri Forest there's deep water to swim in, fences to climb over, things to jump off of, and even a wall to climb (note that he doesn't make it to the top of the wall, but he does latch onto it and climb left and right pretty well).
Why would Dark Link be able to do all these things if the developers didn't intend him to? Well, this is one example where tweaking the game provides some insight into how the game was programmed. It's unlikely that the developers programmed Dark Link to be able to do all these things; it would be a waste of time, considering the room Dark Link was put into for the final game.
My theory is that Dark Link is basically a complete clone of Link himself -- programmatically. Only, instead of having a physical N64 controller held by a human that controls Link's moves, it's a "virtual" N64 controller operated by a simple program. So, when Dark Link approaches Link, the program basically moves its virtual control stick on its virtual controller in the general direction of Link. When Dark Link swings its sword at Link, the program just presses the "B" button on its virtual controller.
This explains why Dark Link is able to swim, climb fences, climb walls, and jump off ledges; all of these actions (for the player) only require you to use the control stick. So, because Dark Link has its own virtual control stick, it can do all these things too (not always perfectly; it couldn't make it to the top of that wall I had it climb).
I just think it's interesting how the developers used this kind of approach to programming Dark Link. Every other enemy in the game has a more proper program to dictate how it behaves. One would assume that Dark Link had a program just like all the other enemies. But as you can see here, Dark Link is the one enemy in the game that stands out, and therefore is the most interesting.
The general code behind Dark Link, I theorize, was also ported over to The Legend of Zelda: Majora's Mask for use with the character Kafei. In Majora's Mask, during a certain side quest you're allowed to take control of Kafei, and the entire sequence involves switching control back and forth between Kafei and Link. This implementation is done poorly and is prone to many glitches, indicating that the Zelda 64 engine wasn't designed to allow switching of characters. Also there are some cheats to switch places with Kafei while in Clock Town, similar to the cheat to switch places with Dark Link, evidencing further that Kafei's code likely evolved from Dark Link's.
showkey`. This program shows you the decimal key code for any key on the keyboard that you type in, and quits after 10 seconds since your last keypress.
More interestingly, it warned me that the X Server was running, and that the results might be off a little because the X Server also reads from /dev/console. Apparently /dev/console outputs some binary for all your keypresses, and only root has read access to it (this is probably a good thing). I'm not sure yet what /dev/console binds to, but it seems that whatever your active console (or X session) is, that's what keypresses can be seen there.
If you do `cat /dev/console` as root and type stuff, the terminal prints two binary characters for each keypress. With this one could theoretically make a keylogger. So, out of boredom and to see if I could, I started writing a Perl script to read from /dev/console. For obvious reasons I won't release any code, but for the curious (and those more knowledgeable than the script kiddies)...
I'm relatively sure that the two bytes should be read together as a signed short 32-bit integer. That is, I convert it to decimal and then 4 hex characters by doing this:
my $dec = unpack("S", $buffer);
my $hex = sprintf("%04x", $dec);
From now on, a "byte" refers to a pair of hexadecimal characters. So "1e9c" is two bytes, 1e and 9c.
It seems that the first byte tends to indicate the key typed on the keyboard, and when converted to decimal shows the same number as showkey does. The second byte might be a modifier on the first byte, for example all four arrow keys send the key code 0xE0 as their first byte, and then the second byte is 0x48 for up, 0x50 for down, 0x4D for right and 0x4B for left.
There's almost no documentation about how to read the binary coming in from /dev/console. I had to look at the source code of showkey.c to get more of an idea. Once I realized that the first byte lines up with the decimal codes given by showkey, that helped a lot. The second byte is weird though: it seems to depend on the character you typed before it. For instance:
1e 9c - Pressed a 1e 9e - Pressed a 1e 9e - Pressed a 30 9e - Pressed b 30 b0 - Pressed b 30 b0 - Pressed b 1e b0 - Pressed a 1e 9e - Pressed a 1e 9e - Pressed a 30 9e - Pressed b 1e b0 - Pressed aSo my Perl script catches a lot of keys, then every now and then the "mode" randomly changes or something and the whole entire keymap gets shifted by about 100; I've figured these were for capital letters or when the shift key was pressed and added the capital letters to my key map, but I don't know why it does this. At any rate, I forgot I left my script running when I locked my screen, and unlocked it to see that it logged my entire password.
It'd be great if there was actually some documentation about this, but I've discovered a lot about it just from tinkering with it so far.
0.0017s.
![]()
{kind=link}
{kind=link}
{kind=link}
{kind=link}