Here's a random idea that just popped into my head: to help with the security of CGI scripts, certain HTML elements in the forms can be "tagged" in various ways depending on what their function will be once submitted.
So a textarea for leaving a comment can be tagged with name="ta-comment" (ta means textarea), and an input box meant for entering user names only could be tagged with name="user-login", and an input box meant for entering numeric zip codes can be tagged name="num-zipcode".
Then, the CGI script, when it first begins parsing the query string and form parameters, can automatically apply global filters to the inputs based on their tag. This way, every input that might potentially be used to access the filesystem can be filtered so that it doesn't contain any special characters that could introduce a vulnerability in the script, but fields that are meant to be more verbatim (i.e. comment boxes) can be left largely untouched.
# Create a CGI object
my $q = new CGI();
# This will hold your script's parameters
my $args = {};
# Get all the params.
foreach my $what ($q->param) {
my $is = $q->param($what);
# Filter the value based on the tag.
if ($what =~ /^num\-/) {
# Numbers only!
$is =~ s/[^0-9]//g;
}
elsif ($what =~ /^user\-/) {
# Usernames are numbers and letters only!
$is =~ s/[^A-Za-z0-9]//g;
}
elsif ($what =~ /^ta\-/) {
# Textareas turn their line breaks into <br>
$is =~ s/\n/<br>/g;
$is =~ s/\x0d//g;
}
$args->{$what} = $is;
}
So this way, as you write your front-end HTML code and the back-end Perl, you can tag all the inputs based on how the back-end code will plan on using them once submitted, and the code that collects the parameters when the form is submitted will be sure to format them in a consistent way. So, if your web application consistently doesn't allow quotation marks or HTML code in their text boxes, you can make the CGI automatically remove these things from all your incoming fields, and then just specially tag the ones that you want to be treated differently.
It would protect against accidental oversights by the programmer, and the end user can't do anything about it either. If the text box's name is "num-zipcode", the CGI script will always remove non-numbers when submitted and the user can't do anything about it. If they try to rename it with Firebug to be "text-zipcode" or anything like that, your CGI script won't use their version because it's not named as "num-zipcode."
I think I'll try implementing something like this next time I create a new web application.
Late last week I started thinking about how to access a webcam device from within Perl. I have no direct need of such capability at the time being but I wanted to know how to do it in case I wanted to do something in the future involving webcams.
A few years ago when I used mostly Windows I found EZTwain, a DLL library for accessing a webcam in Windows using the TWAIN protocol (which as I understand is obsolete by now). The DLL was a pain in the butt to use and I couldn't get it to work how I wanted it to (it insisted on displaying its own GUI windows instead of allowing my Perl script to directly pull a frame from it without a GUI).
Besides that there's pretty much no libraries Perl has been built to use yet that can access a webcam. So, I started looking into using third-party programs such as ffmpeg and mplayer/mencoder to provide the hardware layer for me so that Perl can get just the jpeg images out and do with them what it needs.
Of these programs I wanted to use ffmpeg the most, because I know for sure there's an ffmpeg.exe for Windows, which might mean that whatever code I come up with might be reasonably portable to Windows as well.
After some searching I found some command-line sorcery for using ffmpeg over SSH to activate the camera on a remote computer and stream the video from it over SSH to the local system, and display it in mplayer:
ssh user@remoteip ffmpeg -b 100K -an -f video4linux2 -s 320x240 -r 10 -i /dev/video0 -b 100K -f ogg - | mplayer - -idle -demuxer ogg
Using the basic ffmpeg command in there, along with some hours of research and poking around, I eventually came up with a command that would activate the webcam and output a ton of jpeg images with consecutive file names, of each frame of video that the camera recorded:
ffmpeg -b 100K -an -f video4linux2 -s 640x480 -r 10 -i /dev/video0 -b 100K -f image2 -vcodec mjpeg test%d.jpg
The mjpeg codec (or "motion jpeg"), in ffmpeg, really means it's a bunch of jpeg images all combined together one after the other (the start of each jpeg image can be seen in hex by looking for the magic number, 0xFFD8). The "image2" format here means that each frame from the mjpeg stream gets written to an individual image file, in the format test%d.jpg where %d is a number that goes up for each image written.
By changing the image2 to image2pipe instead, the output (all the jpeg images in the mjpeg stream) is sent through the program's standard output, so it can be piped into another program, or read from in Perl.
So in Perl I opened a pipe that executes this command and have the script read from it, reading all the jpeg images and then displaying them in a Perl/Tk window as they come in. In effect: a live webcam stream, where Perl is entirely in control of the jpegs as they come in from ffmpeg and can do with them whatever it wants!
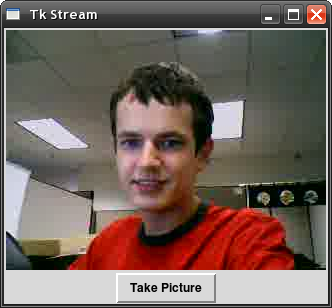
I added a button to my GUI for taking a snapshot and saving it to disk (in actuality, as each complete image is read and displayed, it's kept around in memory until the next image is read and displayed... so this button just saves the last full image to disk).
Here's my proof of concept Perl code:
#!/usr/bin/perl -w
# Perl/Tk Webcam Streamer and Snapshot Taker
# Proof of Concept
# Author: Casey Kirsle, http://www.cuvou.com/
use Tk;
use Tk::JPEG;
use MIME::Base64 "encode_base64";
# Some things that might need to be configured.
my $device = shift(@ARGV) || "/dev/video0";
if ($device =~ /^\// && !-e $device) {
die "Can't see video device: $device";
}
# Tk MainWindow
my $mw = MainWindow->new (
-title => 'Tk Stream',
);
$mw->protocol (WM_DELETE_WINDOW => \&onExit);
# A label to display the photos.
my $photo = $mw->Label ()->pack();
# A button to capture a photo
my $capture = $mw->Button (
-text => "Take Picture",
-command => \&snapshot,
)->pack();
$mw->update();
You can download it here. It should run on any Linux distribution and it depends on having Perl/Tk and ffmpeg installed, and the video4linux2 system (any modern distro will have that).
In the ffmpeg command here you'll see I also piped the output into a quick Perl script that substitutes all the jpeg headers so that they begin with "KIRSLESEP" -- this was to make it easier to split the jpegs up while reading from the stream.
Since this uses ffmpeg and there's an ffmpeg.exe for Windows, this might work on Windows (you'll definitely need to modify the arguments sent to the ffmpeg command, though). I don't currently have access to a Windows machine with a webcam, though, so I can't work on that just yet.
Anyway, here it is: webcam access in Perl!
I got to the office and checked my e-mail and saw that TekTonic (my web hosting company) forwarded an e-mail to me that was sent to their abuse department from another sysadmin, saying that my server's IP has been caught brute-forcing SSH passwords on their server.
So I logged into my server to check things out. My guesses at this point were either: somebody on my server has a weak SSH password, and one of those automated password-guessing bots has cracked it and their account got pwned; or else somebody on my server had something insecure on their site, such as a PHP app or some SSI code, that got compromised and used to attack my server.
After pruning the SSH logs and seeing nothing suspicious, I noticed that the Apache web service was down (so all sites on the server were offline). Apache's been doing this at random intervals so I didn't think much of it just yet and started Apache back up, and then thought to check its global error log file.
Apart from the usual errors that Apache logs here (404 Not Found, etc.) there was other text in the log file that was the output of some commands that would be run at a terminal. Commands like wget (to download files off the Internet), chmod (there were some errors like "chmod: invalid mode 'x'" indicating a badly entered chmod command), and perl (attempting to execute a Perl script).
From reading this in the error log it became apparent that somebody was causing Apache (or at least the user that Apache runs as) to execute system commands. With that, they downloaded a tarball containing exploits from a Geocities site, a tarball containing a backdoor/trojan, and a tarball containing something that they used to "phone home" - probably to make the process of entering commands on my server easier.
In Apache's access log file I was able to see how they were doing this; they were abusing a flaw in phpMyAdmin that allowed them to execute these commands. So, I was right: somebody had a PHP application on their site and this app was used to break into the server. But that somebody was me. :(
So, I was able to see what HTTP requests they were making that was causing phpMyAdmin to execute their commands, and therefore I was able to see all the commands they entered -- or rather, the ones they entered by abusing phpMyAdmin. If the phone home script was indeed used to execute additional commands, they could've run even more after that point (I'm assuming they did, because the initial e-mail I got was about my server guessing SSH passwords on another, and nothing that happened through phpMyAdmin was responsible for that).
I later found out from TekTonic that when they first got the complaint they logged in and killed the Apache-owned process that was brute forcing the SSH passwords. This would explain why Apache was down when I logged in. But the fact that this hacker was running additional commands through the backdoor script that I have no logs of made me decide that reimaging the server would be the best solution. I used to work at a web hosting company and when a customer server got pwned, reinstalling the operating system was the only way to be sure no rootkits were left behind -- especially considering that rootkits these days are pretty crafty and can hide from being listed in the running processes.
I e-mailed the abuse departments at Geocities telling them that one of their users is hosting backdoors and the abuse department of the ISP that controls the IP address of the hacker who broke into my server. Hopefully further action will be done on their parts. The hacker probably won't be found (hackers tend to go through proxy servers like there's no tomorrow), but hopefully whatever server that IP address belongs to can be fixed to prevent further use by the hacker to attack other servers.
Anyway,
This is why I don't like PHP. The exploit in phpMyAdmin was because phpMyAdmin has a PHP file that directly runs system commands based on a query string parameter. This file isn't meant to be executed directly (it's named with a ".inc.php" extension, indicating it was intended to be included by another PHP script and not run directly over the web). But this file was available directly over the web, AND it accepted query string parameters, AND executed those on the system. Terrible! In Perl this kind of thing would never fly. If you did request a Perl included file directly, it wouldn't read your query string parameters, because normally the Perl script that includes it would've done that already.
PHP has too many newbies, and newbies write terrible code. phpMyAdmin could've been smarter than this, but the fact that this happens shows that phpMyAdmin wasn't coded very well at all, probably because its coders are incompetent PHP kiddies.
Anyway, this time around, PHP is NOT installed on my server AT ALL. And if anybody on my server asks for it, to get something like WordPress installed for instance, I'll just kindly point them to MovableType as a Perl alternative to WordPress. WordPress might be a decent PHP application, but it's still a PHP application and I officially will not trust any PHP app written by anyone other than real programmers to be installed on this server again.
PHP programmers who only program PHP basically can be assumed to be completely incompetent and to build in gaping, shameless security holes like what phpMyAdmin had: a script that directly sends query string parameters into a system command unfiltered. PHP programmers who know other programming languages that aren't as newbish as PHP (Perl, for instance) are probably better at coding secure PHP, but besides that I am officially boycotting PHP coders and their applications.
Update #2 (12/02/2014): I've updated ProgramV 0.08 and released a new version, 0.09, which should work out-of-the-box on modern Perl. If you're interested in ProgramV, check it out on GitHub or read my blog post about the update.
The original blog post follows.
Numerous years ago (2002 or 03) while I was a newb at programming my own chatterbots in Perl (and a newb at Perl in general), there was this program called Alicebot Program V - an implementation of an Alice AIML chatbot programmed in Perl.
When I moved from RunABot (hosted AIML bots) and Alicebot Program D (a Java AIML bot) to Perl, I had to give up using AIML for my bots' response engines because there weren't any simple Perl solutions for parsing AIML code. There was only Program V, and Program V is a monster! I could never figure out how to get it to actually run, and, while it had a dozen Perl modules with it that deal with the AIML files, these modules are too integrated together to separate and use in another program.
And then Program V's site went down and for several years I couldn't find a copy of Program V anymore to give it another shot.
Since I effectively could not use AIML for my Perl bots, I eventually developed an alternative bot response language called RiveScript, and it's text-based instead of XML-based, so it's super easy to deal with. At this point I don't care much for AIML any more, because my RiveScript is more powerful than it anyway.
The only thing RiveScript is missing though is Alice - the flagship bot personality of AIML. Alice has about 40,000 patterns that it can respond to. Users chatting with Alice won't get bored with the conversation for a long, long time. Alice has a large enough reply set that you'll have to chat with it a lot before you can start predicting how she might reply to your next message.
RiveScript, being (relatively) new (and not yet as popular as AIML), hasn't seen any large projects like Alice. Alice was written by Dr. Wallace, who created AIML; should I, as the creator of RiveScript, create an Alice-sized reply base myself? Ha. I wish I had that kind of free time on my hands.
So for a really long period of time I was trying to create an AIML-to-RiveScript translator, so that Alice's 40,000 responses of AIML code could become 40,000 responses of RiveScript code. I've finally accomplished this with a really good degree of success recently. So mission accomplished.
Now, while searching for something unrelated, I managed to come across a site that hosted a copy of the Program V code. Now that I'm much more awesome at Perl than I was back then, I downloaded it and tried getting it set up. It took a bit of tinkering (it was programmed on Perl 5.6 and some things have changed between then and 5.10) but I got it up and running.
Program V works in two parts: first you run a "build script," which reads and processes the AIML code and builds a kind of database file (really it's just the result of Data::Dumper, dumping out a large Perl data structure). And then you run the actual bot script, which just loads this data structure from disk. This is because the Alice AIML set (40K replies) takes about 3 to 4 minutes to load, but the Perl data structure takes milliseconds to load. So you build it first to save lots of time when actually running it.
I was impressed at how fast the bot could reply, too. Most of its replies were coming back in 8 milliseconds or less. In contrast, when I load Alice's brain in RiveScript... it takes 5 seconds to load all the RiveScript code from disk (much faster than Program V's loading of AIML), and then Alice will usually reply in less than 1 second, but longer than 8 milliseconds. So, I had a look at this data structure that Program V creates.
In the data structure, all the patterns in AIML are put into a hash, and categorized by the first word in the pattern. Here's just a snippit:
The following patterns are represented here:
ITS *
ITS BORING
ITS FUN
ITS GOOD *
$data = {
aiml => {
matches => {
'ITS' => [
'* <that> * <topic> * <pos> 17818',
'BORING <that> * <topic> * <pos> 17819',
'FUN <that> * <topic> * <pos> 17820',
'GOOD * <that> * <topic> * <pos> 17821',
],
},
},
};
So, since all these patterns began with the word "ITS", they're all categorized under the "ITS"... each item in the array begins with the rest of the pattern (after the word ITS), and then there's separators for the "that", "topic", and "pos" (position). In all the examples here, these patterns had no 'that' or 'topic' tags associated with them, so there's only *'s here. The position is an array index.The templates (responses to these patterns) are all thrown together into a single large array. All those positions listed in the "matches" structure? Those are array indices.
You might need to know a little Perl to see the performance boost here. A good number of patterns in Alice's brain begin with the same word. So when it's time to match a reply from the human, the program can use the first word in your message as a hash key (say you said "It's good to be the king", it would look up the array above based on the word "ITS"). With Alice's brain, there'd be only a few hundred unique first words to patterns. So this is a relatively small hash, and looking up one of these keys such as "ITS" is really fast. Then, each of the arrays here are relatively small, and the program just loops through them to find out if any of them match your message (taking into account the `that`'s and `topic`s too).
When it finds a match, it has an array index of the template for that match. Pulling an array item by index in Perl is even more wicked fast than a hash. So almost instantaneously you can get a response back.
Compared to the Perl module, RiveScript.pm's, data structure, the one used by Program V is much more efficient. In RiveScript.pm everything is arranged in a hierarchy, sorted by: topic, pattern, reply. RiveScript uses arrays in the end to organize the patterns in the most efficient way possible, but when it comes to actually digging out data from this giant hashref structure, it's a little slower than just using an array like Program V.
Still, though, 1 second response times for a brain that contains 40,000 patterns isn't bad. But I might need to think about recoding RiveScript.pm to use more efficient data structures like Program V.
I have a copy of Program V hosted on RiveScript.com here: programv-0.08.tar.
So I've created a web-based converter tool to turn TrueType TTF fonts into OpenType EOT fonts, to go along with my other tools that turn images into favicons and turn images into XBM masks.
You can use the new tool here. As with all the other tools, your converted files are cleared off the server after 24 hours, so don't think about hotlinking your embeddable fonts!
The idea was that there could be a common archive file format (Tyd) that could be used by multiple applications or games, and each application would have its own password for its Tyd archive, that only the application and the developer knows. This would make it at least a little bit difficult for the app's end users to open up the archive and poke around at its contents. Compare this to Blizzard's MPQ archive format used by all their games, where users can easily open them up and get at their contents. With Tyd, they'd need to reverse engineer each application that uses a Tyd archive to open that app's archives.
You can see Archive::Tyd's CPAN page for more details.
This was limited though because, since the whole entire file was encrypted together, the application would need to load the whole archive into memory to be able to use it. So, while it was fine for small archives containing small files, a larger archive would consume too much memory. So forget about storing a lot of MP3s and MPEGs in a Tyd archive unless you're operating a supercomputer.
Also, there was no way to verify that a password to an archive was entered correctly, short of trying to decode it and see if you only get gibberish out of it.
So I started piecing together ideas for a successor to Tyd, which will still be called Tyd (version 2.0). The basic requirements are:
To facilitate "streaming", when the archive is encrypted or compressed, each file is only affected one block at a time. By default the block size is 512 bytes, so when a file is added to an encrypted archive, 512 bytes are encrypted at a time and separately. When reading the file back from the archive, one block at a time is read, decrypted, and returned to the caller (the block size after encryption is surely greater than 512 bytes; when compressed, less than 512 bytes).
For the actual encryption and compression algorithms I'll be using existing CPAN modules to implement known algorithms.
The new Archive::Tyd algorithm is intended to have basically these features:
This way the application can be built to know the public key so it can read the archive, and any user who reverse engineers the application can only get the public key -- so they can get read-only access to the archive, but have a much harder time modifying it or changing its contents without the secret key. IIRC this would be similar to Blizzard's MPQ, in that the DLL that reads MPQ files for their games doesn't include the functions needed to write/modify MPQ files, giving the end users read-only access to the file's contents.
Anyway, no ETA yet, this is a big project. (Well, not really, the heavy lifting of encryption/compression is done by third party modules, all I need to do is program the wrapper code).
The cplusplus.com tutorial only covers the syntax of C++, but doesn't go into anything practical, such as working with more than one source file, or how header files work, or how to compile a program that has multiple files. The tutorial at learncpp.com though covers all of these things and then some -- it even explains how C++ programs are organized and a bunch of other helpful techniques that clears up a lot of the fuzziness that other tutorials leave ya with.
So after a week and change, I've gotten about halfway through the tutorials and am attempting to write my own programs from scratch -- actual programs, not tutorial-like things. So, I've decided to start piecing together a CyanChat library. Why CyanChat? Because of its simplicity:
Programming this CyanChat library so far is a bit more tricky than it was in Perl and Java. There is a full C++ CyanChat client available named Magenta, but looking at its source code doesn't help me very much -- this is a Windows application, and the source file that handles the sockets is an override of the Win32 CSocket library, which is Windows-specific. I want to use something cross-platform.
Right now I'm using the rudesocket C++ library, although I may need to ditch it for something different, because its setTimeout() function doesn't seem to work and so reading from the socket hangs until the server sends data. This isn't scalable.
When I get the library completed, I'll try building it on Windows to get that experience (that'll be a blast...), and then I'll attempt to build a dynamic Windows DLL file from it -- and then link that DLL into Perl using Win32::API -- to see that everything is successful.
My eventual goal in C++ programming is to build a RiveScript interpreter library in it, and build it as a dynamic DLL, so that practically every programming language will then be able to link it and use it (or C/C++ programs can statically link it from its source code if they want). I could even create a Perl module named RiveScript::XS, which compiles statically with the C++ RiveScript interpreter, which might give it additional speed over the pure-Perl RiveScript module -- or again, just to see that it all works how I want it to.
Update (11/25/09): This method is all wrong. Here is the correct way.
A thread on Tek-Tips came up recently about making a progress bar for a file uploader in Perl.
Investigating the issue more closely, I found a couple of commercial solutions (read: paid for), where even their free edition involves thousands upon thousands of lines of code, spread out across many different files. Nowhere to be found was a simple, straight-to-the-point example of how this could be done.
From poking around at what code I could find, I got the basic gist to it:
It looks like this:
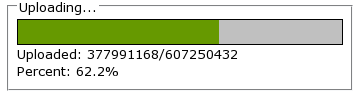
If that sounds complicated, it really isn't. 77 lines for the CGI script, and 126 lines for the HTML page, including the JavaScript (only 60 lines of JavaScript).
The screenshots, code, and download link follow.
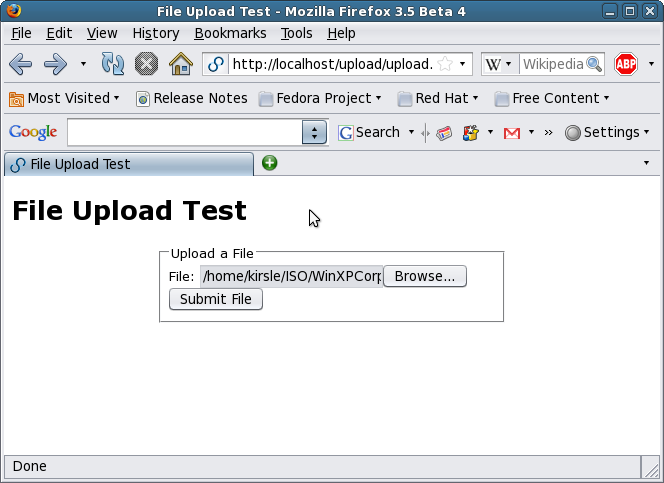 The upload form. Simple.
The upload form. Simple.
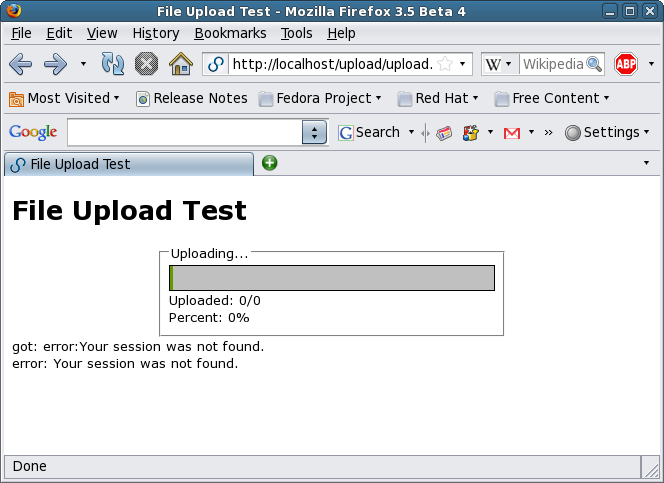 Beginning an upload.
Beginning an upload.
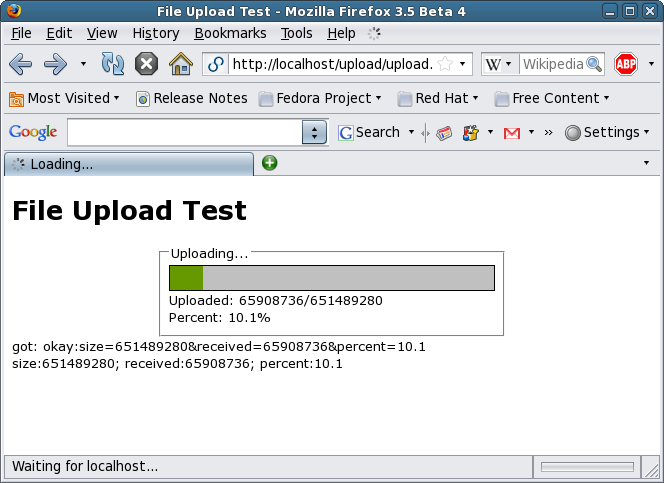 And the progress begins!
And the progress begins!
Source Code:
upload.html (the HTML form and JavaScript)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>File Upload Test</title>
<style type="text/css">
body {
background-color: white;
font-family: Verdana;
font-size: small;
color: black
}
#trough {
background-color: silver;
border: 1px solid black;
height: 24px
}
#bar {
background-color: #669900;
height: 24px;
width: 1%
}
</style>
</head>
<body>
<h1>File Upload Test</h1>
<div id="progress" style="display: none; margin: auto; width: 350px">
<fieldset>
<legend>Uploading...</legend>
<div id="trough"><div id="bar"></div></div>
Uploaded: <span id="uploaded">0</span>/<span id="size">0</span><br>
Percent: <span id="percent">0</span>%
</fieldset>
</div>
<div id="form" style="display: block; margin: auto; width: 350px">
<fieldset>
<legend>Upload a File</legend>
<form name="upload" action="upload.cgi" method="post" enctype="multipart/form-data" onSubmit="return uploadFile(this)">
<input type="hidden" name="action" value="upload">
File: <input type="file" name="file" size="20"><br>
<input type="submit" value="Submit File">
</form>
</fieldset>
</div>
<div id="debug"></div>
<script type="text/javascript">
// When the form is submitted.
function uploadFile(frm) {
// Hide the form.
document.getElementById("form").style.display = "none";
// Show the progress indicator.
document.getElementById("progress").style.display = "block";
// Wait a bit and make ajax requests.
setTimeout("getProgress()", 1000);
return true;
}
// Poll for our progress.
function getProgress() {
var ajax = new XMLHttpRequest();
ajax.onreadystatechange = function() {
if (ajax.readyState == 4) {
gotProgress(ajax.responseText);
}
};
ajax.open("GET", "upload.cgi?action=progress&session=my-session&rand=" + Math.floor(Math.random()*99999), true);
ajax.send(null);
}
// Got an update
function gotProgress(txt) {
document.getElementById("debug").innerHTML = "got: " + txt + "<br>\n";
// Get vars outta it.
var uploaded = 0;
var size = 0;
var percent = 0;
var stat = txt.split(":");
// Was it an error?
if (stat[0] == "error") {
document.getElementById("debug").innerHTML += "error: " + stat[1];
setTimeout("getProgress()", 1000);
return false;
}
// Separate the vars.
var parts = stat[1].split("&");
for (var i = 0; i < parts.length; i++) {
var halves = parts[i].split("=");
if (halves[0] == "received") {
uploaded = halves[1];
}
else if (halves[0] == "percent") {
percent = halves[1];
}
else if (halves[0] == "size") {
size = halves[1];
}
}
document.getElementById("debug").innerHTML += "size:" + size + "; received:" + uploaded + "; percent:" + percent + "<br>\n";
// Update the display.
document.getElementById("bar").style.width = parseInt(percent) + "%";
document.getElementById("uploaded").innerHTML = uploaded;
document.getElementById("size").innerHTML = size;
document.getElementById("percent").innerHTML = percent;
// Set another update.
setTimeout("getProgress()", 1000);
return true;
}
</script>
</body>
</html>
upload.cgi (the CGI script)
#!/usr/bin/perl -w
use strict;
use warnings;
use CGI;
use CGI::Carp qw(fatalsToBrowser);
my $q = new CGI();
# Handle actions.
if ($q->param('action') eq "upload") {
# They just submitted the form and are sending a file.
my $filename = $q->param('file');
my $handle = $q->upload('file');
$filename =~ s/(?:\\|\/)([^\\\/]+)$/$1/g;
# File size.
my $size = (-s $handle);
# This session ID would be randomly generated for real.
my $sessid = 'my-session';
# Create the session file.
open (CREATE, ">./sessions/$sessid") or die "can't create session: $!";
print CREATE "size=$size&file=$filename";
close (CREATE);
# Start receiving the file.
open (FILE, ">./files/$filename");
while (<$handle>) {
print FILE;
}
close (FILE);
# Delete the session.
unlink("./sessions/$sessid");
# Done.
print $q->header();
print "Thank you for your file. <a href=\"files/$filename\">Here it is again</a>.";
}
elsif ($q->param('action') eq "progress") {
# They're checking up on their progress; get their sess ID.
my $sessid = $q->param('session') || 'my-session';
print $q->header(type => 'text/plain');
# Does it exist?
if (!-f "./sessions/$sessid") {
print "error:Your session was not found.";
exit(0);
}
# Read it.
open (READ, "./sessions/$sessid");
my $line = <READ>;
close (READ);
# Get their file size and name.
my ($size,$name) = $line =~ /^size=(\d+)&file=(.+?)$/;
# How much was downloaded?
my $downloaded = -s "./files/$name";
# Calculate a percentage.
my $percent = 0;
if ($size > 0) {
$percent = ($downloaded / $size) * 100;
$percent =~ s/\.(\d)\d+$/.$1/g;
}
# Print some data for the JS.
print "okay:size=$size&received=$downloaded&percent=$percent";
exit(0);
}
else {
die "unknown action";
}
Notes on this code: it's just a proof of concept. You'd want to handle the sessions better. Here the session ID is hard-coded as "my-session" -- that wouldn't work in real life. But it's just a barebones working implementation of a file upload progress bar, with all the crap cut out and does specifically what it's supposed to. Others should find it useful, so you can download it.
Update (11/25/09): This method is all wrong. Here is the correct way.
And today is one such day that I tried to SSH home and got a "Connection refused", because my IP had changed. My bot told me what my new address was, and all was good.
Which brings me to my next point: the program I wrote for my bots I named AiRS (Artificial Intelligence: RiveScript). If any of my readers know me from when I used to run AiChaos.com, this bot is sort of like my Juggernaut and Leviathan programs. The bot can run multiple connections (mirrors) to multiple listeners (so far, AIM and HTTP, but I'll be adding MSN Messenger support shortly). Unlike Juggernaut and Leviathan, though, the program uses RiveScript and RiveScript only as the reply engine.
By the time I release the program it will definitely have support for AIM, MSN, IRC, and HTTP. Other listeners? Maybe, maybe not. Jabber is a possibility. It will depend on what existing modules are available, how usable they are, how well they work, etc.
At any rate, you can chat with my AIM bot by sending an IM to AiRS Aiden. So far it just chats, but it can also tell you how the weather is, play mad libs, and do a couple less cool things.
<a href="/index.cgi?p=blog;tag=General"> as opposed to <a href="/index.cgi?p=blog&tag=General">The reasoning behind it was something along these lines:
&" characters should be fully typed out as "&", because HTML 4.01 no longer allows a single & without any kind of escape sequence following it.
So, http://www.cuvou.com/?p=blog;id=36 looks right in the Google search results, but after it gets chewed up with Google's outgoing statistic gathering and finally accessed by the browser, the latter part of that request comes to my site looking more like this: /?p=blog%3Bid=36. CGI.pm has no idea what to make of this and it can't be blamed. I've tried substituting it in $ENV{QUERY_STRING} before CGI.pm can get its hands on it, but it doesn't help.
So effectively the user is greeted with a "Forbidden" page of mine, which was fired because the value of "p=" contains some invalid character (notably, that % symbol there).
So there's a conundrum here: semicolons as delimiters works as far as CGI is concerned, and it perfectly validates as HTML 4.01 Strict, and you don't need to write "&" all the time inside your internal site links. I mean seriously, how ugly is this HTML code?
<a href="/index.cgi?p=blog&id=36">It validates, it works as expected provided you're using it "properly", however it breaks your links in Google and possibly other search engines, at least in Firefox.
For my CMS, none of my links are "properly" written to begin with. They're like <a href="$link:blog;id=36"> which is translated on-the-fly, so it was fairly trivial to change the code to fix these things on the way out the door.
For the W3C's HTML validator, my links are translated to include the full and proper & text. It's ugly and I'm only glad I don't have to write the links like that directly; my Perl code does it for me.
The other half of the dirty hack is to detect when a troublesome URL has been linked to: particularly if %3B is found. If so, the CGI fixes the query string and sends an HTTP 301 redirect to the proper version of the URL, using the real semicolons (I could replace them with &'s here, but, why? The CGI module takes care of it anyway ;-) ).
I'll have to investigate what other web developers do with their query string delimiters...
0.0016s.
![]()